Q-Learning算法
强化学习是机器学习大家族中的一大类, 使用强化学习能够让机器学着如何在环境中拿到高分, 表现出优秀的成绩. 而这些成绩背后却是他所付出的辛苦劳动, 不断的试错, 不断地尝试, 累积经验, 学习经验.
1、算法思想
QLearning是强化学习算法中value-based的算法,Q即为Q(s,a)就是在某一时刻的 s 状态下(s∈S),采取 动作a (a∈A)动作能够获得收益的期望,环境会根据agent的动作反馈相应的回报reward r,所以算法的主要思想就是将State与Action构建成一张Q-table来存储Q值,然后根据Q值来选取能够获得最大的收益的动作。
| Q-Table | a1 | a2 |
|---|---|---|
| s1 | q(s1,a1) | q(s1,a2) |
| s2 | q(s2,a1) | q(s2,a2) |
| s3 | q(s3,a1) | q(s3,a2) |
2、公式
举个例子如图有一个GridWorld的游戏从起点出发到达终点为胜利掉进陷阱为失败。智能体(Agent)、环境状态(environment)、奖励(reward)、动作(action)可以将问题抽象成一个马尔科夫决策过程,我们在每个格子都算是一个状态s(t) , π(a|s)在s状态下采取动作a策略 。 P(s’|s,a)也可以写成P (a|ss’)为在s状态下选择a动作转换到下一个状态s’的概率。R(s’|s,a)表示在s状态下采取a动作转移到s’的奖励reward,我们的目的很明确就是找到一条能够到达终点获得最大奖赏的策略。

根据以上推导可以对Q值进行计算,所以有了Q值我们就可以进行学习,也就是Q-table的更新过程,其中α为学习率γ为奖励性衰变系数,采用时间差分法的方法进行更新。
所以目标就是求出累计奖励最大的策略的期望:
$$
Goal:max_πE[∑^H_{t=0}γ^tR(S_t,A_ t,S_t+1)∣π]
$$
Qlearning的主要优势就是使用了时间差分法TD(融合了蒙特卡洛和动态规划)能够进行离线学习, 使用bellman方程可以对马尔科夫过程求解最优策略
3、更新公式
根据以上推导可以对Q值进行计算,所以有了Q值我们就可以进行学习,也就是Q-table的更新过程,其中α为学习率γ为奖励性衰变系数,采用时间差分法的方法进行更新。
Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)−Q(s,a)]
上式就是Q-learning更新的公式,根据下一个状态s’中选取最大的Q ( s ′ , a ′ ) Q(s’,a’)值乘以衰变γ加上真实回报值最为Q现实,而根据过往Q表里面的Q(s,a)作为Q估计。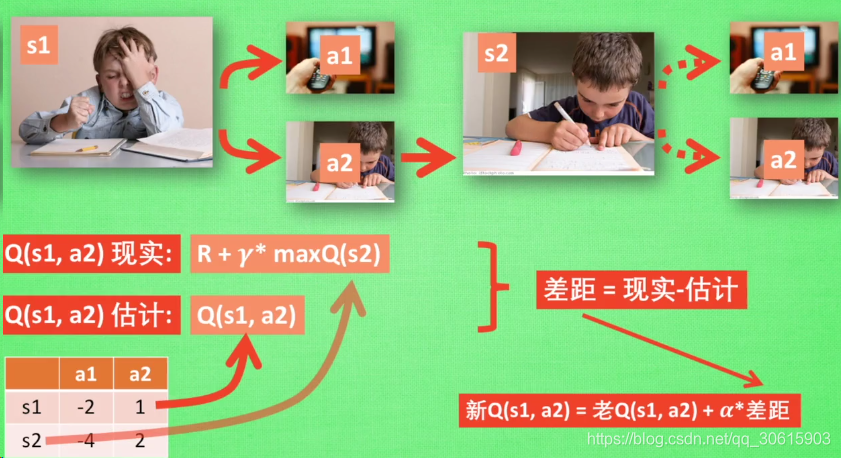

4、实现代码
案例一宝藏在右边
用查表Q学习法进行强化学习的一个简单例子。
代理“o”在一维世界的左边,宝藏在最右边。
运行这个程序,看看代理将如何改善其寻找宝藏的策略。
源码:treasure_on_right.py
import numpy as np
import pandas as pd
import time
np.random.seed(2)
N_STATES = 6 #状态 the length of the 1 dimensional world
ACTIONS = ['left', 'right'] #动作 available actions
EPSILON = 0.9 #贪婪 greedy police
ALPHA = 0.1 #学习率 learning rate
GAMMA = 0.9 #衰减因子 discount factor
MAX_EPISODES = 13 #整体最大的回合 maximum episodes
FRESH_TIME = 0.3 #每走一步的时间间隔 fresh time for one move
def build_q_table(n_states, actions):
table = pd.DataFrame(
np.zeros((n_states, len(actions))), # q_table initial values
columns=actions, # actions's name
)
# print(table) # show table
return table
def choose_action(state, q_table):
# This is how to choose an action
state_actions = q_table.iloc[state, :]
# 默认uniform()返回0到1的数字
# if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): #全为0时才随机选 act non-greedy or state-action have no value
if (np.random.uniform() > EPSILON) or (state_actions.all()==0): #全为0时才随机选 act non-greedy or state-action have no value
action_name = np.random.choice(ACTIONS)
else: # act greedy
action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer version of pandas
return action_name
def get_env_feedback(S, A):#环境
# This is how agent will interact with the environment
if A == 'right': # move right
# 因为后面的S从0开始,所以S的下一个状态即S_到达N_STATES-1时就为终点了即S要STATE-2
if S == N_STATES - 2: # terminate
S_ = 'terminal'
R = 1
else:
S_ = S + 1
R = 0
else: # move left
R = 0
if S == 0:
S_ = S # reach the wall
else:
S_ = S - 1
return S_, R
# episode:回合里的插曲,step_counter:步骤数
def update_env(S, episode, step_counter):
# This is how environment be updated
env_list = ['-']*(N_STATES-1) + ['T'] # '---------T' our environment
if S == 'terminal':
interaction = 'Episode %s: total_steps = %s' % (episode+1, step_counter)
print('\r{}'.format(interaction), end='')
time.sleep(2)
print('\r ', end='')
else:
env_list[S] = 'o'
interaction = ''.join(env_list)
print('\r{}'.format(interaction), end='')
time.sleep(FRESH_TIME)
def rl():
# main part of RL loop
q_table = build_q_table(N_STATES, ACTIONS)
for episode in range(MAX_EPISODES):
step_counter = 0
S = 0
is_terminated = False
update_env(S, episode, step_counter)
while not is_terminated:#进行循环
A = choose_action(S, q_table)
S_, R = get_env_feedback(S, A) # take action & get next state and reward
q_predict = q_table.loc[S, A]#估计值
if S_ != 'terminal':
q_target = R + GAMMA * q_table.iloc[S_, :].max() #真实值 next state is not terminal
else:
q_target = R # next state is terminal
is_terminated = True # terminate this episode
q_table.loc[S, A] += ALPHA * (q_target - q_predict) # update
S = S_ # move to next state
update_env(S, episode, step_counter+1)
step_counter += 1
return q_table
if __name__ == "__main__":
q_table = rl()
print('\r\nQ-table:\n')
print(q_table)
效果:总结走每一步下选择左右的Q值

案例二:走迷宫
黄色的是天堂 (reward 1), 黑色的地狱 (reward -1). 大多数 RL 是由 reward 导向的, 所以定义 reward 是 RL 中比较重要的一点.
源码:maze_env.py
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example. The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import time
import sys
# if sys.version_info.major == 2:
# import Tkinter as tk
# else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
s_ = 'terminal'
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
s_ = 'terminal'
else:
reward = 0
done = False
return s_, reward, done
def render(self):
time.sleep(0.1)
self.update()
def update():
for t in range(10):
s = env.reset()
while True:
env.render()
a = 1
s, r, done = env.step(a)
if done:
break
源码:RL_brain.py
import numpy as np
import pandas as pd
class QLearningTable:
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = actions # a list
self.lr = learning_rate #学习率
self.gamma = reward_decay#奖励衰减
self.epsilon = e_greedy#贪婪因子
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
def choose_action(self, observation):
self.check_state_exist(observation)#判断观察的状态是否在Qtable中
# action selection
if np.random.uniform() < self.epsilon:#随机数小于0.9,按照最优结果选择action
# choose best action
state_action = self.q_table.loc[observation, :]
# 有些动作可能有相同的值,在这些动作中随机选择 some actions may have the same value, randomly choose on in these actions
action = np.random.choice(state_action[state_action == np.max(state_action)].index)
else:
# choose random action
action = np.random.choice(self.actions)#按照随机的方法选择action
return action
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]#预测值
if s_ != 'terminal':#下一步状态不是终点
q_target = r + self.gamma * self.q_table.loc[s_, :].max() #真实值 next state is not terminal
else:#下一步状态是终点
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
源码:run_this.py
from maze_env import Maze
from RL_brain import QLearningTable
def update():
for episode in range(100):
# initial observation
observation = env.reset()
while True:
# fresh env
env.render()
# RL choose action based on observation
action = RL.choose_action(str(observation))
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# RL learn from this transition
RL.learn(str(observation), action, reward, str(observation_))
# swap observation
observation = observation_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = QLearningTable(actions=list(range(env.n_actions)))
env.after(100, update)
env.mainloop()
效果展示