使用Pandas.eval()实现高性能运算
1、pandas中的函数eval()能够将字符串对象转化为有效的表达式,进行求值运算并返回结果;
一般地,运算简单或DataFrame数据量较少之时不适用eval()函数,在DataFrame大于10000行时使用eval(),性能会得到明显提升。
import numpy as np
import pandas as pd
nrows=20000
nclos=200
df1,df2,df3,df4 = [pd.DataFrame(np.random.randn(nrows,nclos)) for i in range(4)]
%timeit df1+df2+df3+df4
32.3 ms ± 256 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit pd.eval('df1+df2+df3+df4')
16.6 ms ± 277 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
其中:魔术命令%timeit可自动多次执行语句,产生一个较为精准的平均执行时间。
使用np.allclose()比较两个数组是否完全相同,结果为True表示eval函数计算结果与普通Pandas计算结果一致。
np.allclose(df1+df2+df3+df4,pd.eval('df1+df2+df3+df4'))
True
2、eval()支持的运算方式
eval()函数支持多种运算方式,如:算数运算、比较运算和布尔运算,同时也支持对象属性与索引的表达方式;
eval()函数目前还不支持函数条用,if条件语句,循环语句及更为复杂的运算。
3、DataFrame.eval()实现列间运算
4、DataFrame.eval()使用局部变量
通过@符号使用Python的局部变量,@符号表示其后紧随的是一个变量名称而不是列名称,如下:
df = pd.DataFrame({'class':['A','A','B','B','C','A'],
'name':['Bob','Bob','Mark','Miki','Sully','Rose'],
'city':['广州市','深圳市','上海市','重庆市','贵州市','北京市'],
'sex':['女','男','女','女','女','男'],
'score_math':[99,99,87,77,77,65],
'score_music':[78,81,91,72,67,99],})
df.eval("sex=='女'and score_math>80")
#新增列
df.eval('sum_score = score_math + score_music',inplace=True)
#修改列
# df.eval('score_math = score_math +5')
df
| city | class | name | score_math | score_music | sex | sum_score | |
|---|---|---|---|---|---|---|---|
| 0 | 广州市 | A | Bob | 99 | 78 | 女 | 177 |
| 1 | 深圳市 | A | Bob | 99 | 81 | 男 | 180 |
| 2 | 上海市 | B | Mark | 87 | 91 | 女 | 178 |
| 3 | 重庆市 | B | Miki | 77 | 72 | 女 | 149 |
| 4 | 贵州市 | C | Sully | 77 | 67 | 女 | 144 |
| 5 | 北京市 | A | Rose | 65 | 99 | 男 | 164 |
add = pd.Series([1,2,3,4,5,6,7,8])
df.eval('score_math+@add')
0 100.0
1 101.0
2 90.0
3 81.0
4 82.0
5 71.0
6 NaN
7 NaN
dtype: float64
DataFrame.query()方法
query()可以实现查询过滤的功能,其用于与DataFrame.eval()类似。
注意:DtaFrame.eval()尽心相同运算时返回的是布尔值
df.query("score_math>85 & score_music>85")
| city | class | name | score_math | score_music | sex | sum_score | |
|---|---|---|---|---|---|---|---|
| 2 | 上海市 | B | Mark | 87 | 91 | 女 | 178 |
数据透视表
一种交互式的表,可进行如求和与计算等操作。可以动态的改变版面布置,会立即按照新的布置重新计算数据。
在数据与探索和数据整理时比较常用。
数据透视表的创建
方法一:pd.pivot_table(data,)
方法二:data.pivot_table()
pivot_table常用参数
参数 说明
index 指定索引,在数据透视表中按行分组
values 选择显示的或需要进行聚合运算的列
columns 将values按所选列进行分组
aggfunc 聚合运算的方法
fill_value 将缺失值替换成指定值
dropna 默认为True,不包含全部为缺失值的列
margins 添加行/列的总计数据,默认是False
margins_name 命名添加的行/列总计数据
#默认求均值
df.pivot_table(index='sex')
| score_math | score_music | sum_score | |
|---|---|---|---|
| sex | |||
| 女 | 85 | 77 | 162 |
| 男 | 82 | 90 | 172 |
df.pivot_table(index='sex',aggfunc = np.max)
| city | class | name | score_math | score_music | sum_score | |
|---|---|---|---|---|---|---|
| sex | ||||||
| 女 | 重庆市 | C | Sully | 99 | 91 | 178 |
| 男 | 深圳市 | A | Rose | 99 | 99 | 180 |
df.pivot_table(index=['sex','class'])
| score_math | score_music | sum_score | ||
|---|---|---|---|---|
| sex | class | |||
| 女 | A | 99.0 | 78.0 | 177.0 |
| B | 82.0 | 81.5 | 163.5 | |
| C | 77.0 | 67.0 | 144.0 | |
| 男 | A | 82.0 | 90.0 | 172.0 |
values—显示需要进行聚合运算的类
columns—设置分组方式
df.pivot_table(index='sex',values='score_math')
| score_math | |
|---|---|
| sex | |
| 女 | 85 |
| 男 | 82 |
#columns表示根据class将数学分数进行纵向分组
df.pivot_table(index='sex',values='score_math',columns='class')
| class | A | B | C |
|---|---|---|---|
| sex | |||
| 女 | 99.0 | 82.0 | 77.0 |
| 男 | 82.0 | NaN | NaN |
values和columns的区别
values选择的列是希望在表中展示的数值,聚合函数aggfunc最终将应用到该值之上
columns选择的列是在提供一个将values的值进行纵向分组的方式
aggfunc传入Numpy函数
传入一个一个函数就进行一次计算,传入多个函数就进行多次计算
margins添加行/列总计
df.pivot_table(index='sex',values='score_math',columns='class',margins = True)
| class | A | B | C | All |
|---|---|---|---|---|
| sex | ||||
| 女 | 99.000000 | 82.0 | 77.0 | 85.0 |
| 男 | 82.000000 | NaN | NaN | 82.0 |
| All | 87.666667 | 82.0 | 77.0 | 84.0 |
margins_name:对 margins进行命名
df.pivot_table(index='sex',values='score_math',columns='class',margins = True,margins_name = 'all_mean')
| class | A | B | C | all_mean |
|---|---|---|---|---|
| sex | ||||
| 女 | 99.000000 | 82.0 | 77.0 | 85.0 |
| 男 | 82.000000 | NaN | NaN | 82.0 |
| all_mean | 87.666667 | 82.0 | 77.0 | 84.0 |
分类数据
分类数据(Category Data)是指Pandas数据类型为分类类型的数据
分类数据是由固定的且数量有限的变量组成,通常是字符串。
df.dtypes
city object
class object
name object
score_math int64
score_music int64
sex object
sum_score int64
dtype: object
使用astype()将性别转换成分类类型
sex_cate = df['sex'].astype('category')
分类数据的values
分类数据的values值是一个pandas.Categorical对象,而不再是Numpy对象
分类数据的属性
包括类别(categories)和编码(codes)两个属性;
分类数据将一个类别映射到一个整数上,其内部数据结构有一个类别数组和一个整数数组构成
sex_cate.values
[女, 男, 女, 女, 女, 男]
Categories (2, object): [女, 男]
#查看类别
sex_cate.values.categories
Index(['女', '男'], dtype='object')
# 查看编码
sex_cate.values.codes
array([0, 1, 0, 0, 0, 1], dtype=int8)
使用分类数据的好处
分类数据通过将类别进行数字编码,可以大大节省内存的占用,提高运行速度,可使用memory_usage()检验
分类数据可以指定逻辑顺序,并能够进行逻辑顺序上的排序和筛选最大/最小值的操作
使用Series.cat.as_ordered()可设置逻辑顺序,但并没有什么实际含义,并不怎么常用
df['class'].astype('category').cat.as_ordered()
0 A
1 A
2 B
3 B
4 C
5 A
dtype: category
Categories (3, object): [A < B < C]
使用Series.cat.set_categories()自定义逻辑顺序,有实际含义
df['class'].astype('category').cat.set_categories(["C","B","A"])
0 A
1 A
2 B
3 B
4 C
5 A
dtype: category
Categories (3, object): [C, B, A]
分类数据的排序仍然使用sort_values()
df['class'].astype('category').cat.set_categories(['C','B','A']).sort_values()
4 C
2 B
3 B
0 A
1 A
5 A
dtype: category
Categories (3, object): [C, B, A]
筛选最大值与最小值
df['class'].astype('category').cat.as_ordered().max()
'C'
df['class'].astype('category').cat.as_ordered().min()
'A'
通过参数dtype创建分类数据
创建Series或DataFrame时,可指定参数dtype = ‘category’创建Series或DataFrame
#创建DataFrame
dfa = pd.DataFrame({'sex':['female','male','male'],'grade':list('BAB')},dtype='category')
dfa.dtypes
grade category
sex category
dtype: object
通过pd.Categorical对象创建分类数据
创建一个pd.Categorical对象,并将其传入Series或者DataFrame,即可创建分类数据
c_df = pd.Categorical({'sex':['female','male','male'],'grade':list('BAB')})
c_df
[sex, grade]
Categories (2, object): [grade, sex]
c = pd.Categorical(['C','A','B'])
dfb= pd.DataFrame({'sex':['female','male','male']})
dfb['grade'] = c
dfb.dtypes
sex object
grade category
dtype: object
在创建pd.Categorical对象时,可以通过参数categoeies指定类别,没被指定的数据则会显示为缺失值
c = pd.Categorical(['C','A','B','A'],categories=['A','B'])
s = pd.Series(c)
s
0 NaN
1 A
2 B
3 A
dtype: category
Categories (2, object): [A, B]
通过pd.Categorical.from_codes创建分类数据
当已知类别编码时,可通过pd.Categorical.from_codes创建分类数据;
categories = ['female','male']
codes = [1,1,1,0,0,1,0]
c = pd.Categorical.from_codes(codes,categories)
c
[male, male, male, female, female, male, female]
Categories (2, object): [female, male]
此时的categories = [‘female’,’male’]的对应的codes值分别为0,1
通过cut()/qcut()创建分类数据—分类数值型数据
使用cut()/qcut()进行离散化会自动转为分类类型
df = pd.DataFrame({'class':['A','A','B','B','C','A'],
'name':['Bob','Bob','Mark','Miki','Sully','Rose'],
'city':['广州市','深圳市','上海市','重庆市','贵州市','北京市'],
'sex':['女','男','女','女','女','男'],
'score_math':[69,99,87,77,77,65],
'score_music':[78,81,91,72,67,99],})
math = pd.cut(df['score_math'],[0,60,80,100],right=False)
math[:3]
0 [60, 80)
1 [80, 100)
2 [80, 100)
Name: score_math, dtype: category
Categories (3, interval[int64]): [[0, 60) < [60, 80) < [80, 100)]
#使用参数lables修改类别名称
math = pd.cut(df['score_math'],[0,60,80,100],right=False,labels=['C','B','A'])
math[:3]
0 B
1 A
2 A
Name: score_math, dtype: category
Categories (3, object): [C < B < A]
结合groupby()查看分类数据,例:修改后的成绩等级无法看到分数区间的范围,可结合groupby查看各最大值、最小值等:
df['score_math'].groupby(math).agg(['count','max','min'])
| count | max | min | |
|---|---|---|---|
| score_math | |||
| C | 0 | NaN | NaN |
| B | 4 | 77.0 | 65.0 |
| A | 2 | 99.0 | 87.0 |
分类数据的特殊属性Series.cat
包含分类数据的Series有很多操作方法,可通过特殊属性Series.cat访问;
通过Series.cat查看其类别categories和编码codes.
s = pd.Series(pd.Categorical(['C','A','B','C']))
# s.cat.categories
s.cat.codes
0 2
1 0
2 1
3 2
dtype: int8
分类数据的常用操作方法
方法 说明
rename_categories 更改类别名称
add_categories 添加新类别
remove_categories 删除类别
remove_unused_categories 删除数据中没有出现的类别
set_categories 替换、增加和删除类别
as_ordered 分类数据设置有逻辑顺序
as_unordered 分类数据设置无逻辑顺序
reorder_categories 重排分类数数据的顺序
更改类别名称—–可通过传入字典的方式进行更改
s1 = s.cat.rename_categories({'A':'grade A','B':'grade B','C':'grade C'})
s1
0 C
1 A
2 B
3 C
dtype: category
Categories (3, object): [A, B, C]
# 添加新类别
s2 = s.cat.add_categories('D')
s2
0 C
1 A
2 B
3 C
dtype: category
Categories (4, object): [A, B, C, D]
删除类别
注意:被删除的类别在数据集中显示值为空值
s3 = s2.cat.remove_categories('D')
s4 = s2.cat.remove_categories('A')
s4
0 C
1 NaN
2 B
3 C
dtype: category
Categories (3, object): [B, C, D]
删除数据中没有出现的类别,remove_categories只能删除某一特定的类别,并不能确定哪些类别并未使用过
s2
0 C
1 A
2 B
3 C
dtype: category
Categories (4, object): [A, B, C, D]
s5 = s2.cat.remove_unused_categories()
s5
0 C
1 A
2 B
3 C
dtype: category
Categories (3, object): [A, B, C]
同时添加或删除类别,使用set_categories,只需将需要的类别直接set即可
s6 = s2.cat.set_categories(['B','C','E'])
s6
0 C
1 NaN
2 B
3 C
dtype: category
Categories (3, object): [B, C, E]
设置逻辑顺序
分类数据的逻辑顺序可以通过as_ordered进行设置,也可以通过as_unordered设置为无逻辑顺序
s_ordered = s2.cat.as_ordered()
s_ordered
0 C
1 A
2 B
3 C
dtype: category
Categories (4, object): [A < B < C < D]
s_unordered = s_ordered.cat.as_unordered()
s_unordered
0 C
1 A
2 B
3 C
dtype: category
Categories (4, object): [A, B, C, D]
在设置分类数据时,也可通过设置参数ordered = True设置逻辑顺序
s_ordered_new = s2.cat.set_categories(['C','B','A'],ordered=True)
s_ordered_new
0 C
1 A
2 B
3 C
dtype: category
Categories (3, object): [C < B < A]
重排逻辑顺序
方法一:前面已介绍,可通过set_categories自定义逻辑顺序
方法二:通过reorde_categories方法重排逻辑顺序
注意:使用reorder_categories方法不能添加或删除类别,否则会报错
s_or = s.cat.reorder_categories(['B','C','A'],ordered=True)
s_or
0 C
1 A
2 B
3 C
dtype: category
Categories (3, object): [B < C < A]
重采样与频率转换(升降采样、resample()、OHLC、groupby()重采样)
重采样(resampling)指的是将时间序列从一个频率转换到另一个频率的过程,其中:
高频转为低频成为降采样(下采样)
低频转为高频成为升采样(上采样)
别名 偏移量类型 说明
D Day 每日历日
B BusinessDay 每日历日
H Hour 每小时
T/min Minute 每分钟
S Second 每秒钟
M MonthEnd 每月最后一个日历日
BM BusinessMonthEnd 每月最后一个工作日
Q-JAN、Q-FRB QuarterEnd 对于以指定月份结束的年度,每季度最后一月的最后一个日历日
A-JAN、A-FEB YearEnd 每年指定月份的最后一个日历日
1、使用resample()方法进行重采样
例:现有一个以年月日为索引的时间序列ts,将其重采样为年月的频率,并计算均值
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
ts = pd.Series(np.random.randint(0,10,5))
ts.index = pd.date_range('2020-7-30',periods=5)
ts
2020-07-30 7
2020-07-31 6
2020-08-01 6
2020-08-02 3
2020-08-03 7
Freq: D, dtype: int32
ts.resample('M').mean()
2020-07-31 4.500000
2020-08-31 4.333333
Freq: M, dtype: float64
2、降采样
使用resample()对数据进行降采样时,需要考虑两个问题:
各区间那边是闭合的(close参数的值–right即又边界闭合,left即左边界闭合)
如何标记各个聚合面元,用区间的开头还是末尾
例:通过求和的方式将上述数据聚合到2分钟的集合里,传入close=’right’会让右边界闭合,传入close=’left’会让左边界闭合
ts = pd.Series(np.random.randint(0,10,5))
ts.index = pd.date_range('2020-7-30',periods=5)
ts
2020-07-30 7
2020-07-31 1
2020-08-01 7
2020-08-02 5
2020-08-03 0
Freq: D, dtype: int32
ts.resample('M',closed='right').sum()
2020-07-31 9
2020-08-31 12
Freq: M, dtype: int32
ts.resample('M',closed='left').sum()
2020-07-31 7
2020-08-31 13
Freq: M, dtype: int32
可以使用loffset设置索引位移,传入参数loffset一个字符串或者偏移量,即可实现对结果索引的一些位移
ts.resample('M',loffset='-1D').sum()
2020-07-30 8
2020-08-30 12
dtype: int32
ts.resample('2M',loffset='-1D').sum()
2020-07-30 8
2020-09-29 12
dtype: int32
3、OHLC重采样
金融领域中有一种时间序列聚合方式(OHLC),计算各面元的四个值:
O:open,开盘
H:high,最大值
L:low,最小值
C:close,收盘
其后也不单单用于金融领域,O可以用于表达初始值,H表示最大值,L表示最小值,C表示末尾值。
传入how = ‘ohlc’可得到一个含有这四种聚合值的DateFrame,但是格式已经改变,如下:
ts.resample('M',closed = 'right',how = 'ohlc')
E:\anaconda\lib\site-packages\ipykernel_launcher.py:1: FutureWarning: how in .resample() is deprecated
the new syntax is .resample(...).ohlc()
"""Entry point for launching an IPython kernel.
| open | high | low | close | |
|---|---|---|---|---|
| 2020-07-31 | 7 | 7 | 1 | 1 |
| 2020-08-31 | 7 | 7 | 0 | 0 |
ts.resample('2M',closed = 'right').ohlc()
| open | high | low | close | |
|---|---|---|---|---|
| 2020-07-31 | 7 | 7 | 1 | 1 |
| 2020-09-30 | 7 | 7 | 0 | 0 |
3、groupby重采样
例:若有一时间序列数据,如何在每月月末显示该月数据的均值
无需用到 rollback 滚动,只需传入一个能够访问 ts 索引上的月份字段的函数即可
rng = pd.date_range('2020-1-14',periods=100,freq='D')
ts = pd.Series(np.random.randint(0,10,100),index=rng)
ts.groupby(lambda x:x.month).mean()
1 3.944444
2 5.344828
3 4.258065
4 5.000000
dtype: float64
根据星期几对上述时间序列进行分组并求出分组后的均值,只需传一个能够访问ts索引上的星期字段函数即可
ts.groupby(lambda x:x.weekday).mean()
0 5.285714
1 4.533333
2 4.000000
3 3.142857
4 6.071429
5 4.214286
6 5.571429
dtype: float64
4、升采样
在将数据从低频转换到高频时,不需要聚合。
data = pd.DataFrame(np.random.randint(0,10,size=(2,4)))
data.index = pd.date_range('2020-1-14',periods = 2,freq='W-WED')
data.columns = ['one','two','three','four']
data
| one | two | three | four | |
|---|---|---|---|---|
| 2020-01-15 | 8 | 3 | 6 | 1 |
| 2020-01-22 | 6 | 5 | 0 | 2 |
将data重采样到日频率,默认会引入缺失值
data.resample('D').mean()
| one | two | three | four | |
|---|---|---|---|---|
| 2020-01-15 | 8.0 | 3.0 | 6.0 | 1.0 |
| 2020-01-16 | NaN | NaN | NaN | NaN |
| 2020-01-17 | NaN | NaN | NaN | NaN |
| 2020-01-18 | NaN | NaN | NaN | NaN |
| 2020-01-19 | NaN | NaN | NaN | NaN |
| 2020-01-20 | NaN | NaN | NaN | NaN |
| 2020-01-21 | NaN | NaN | NaN | NaN |
| 2020-01-22 | 6.0 | 5.0 | 0.0 | 2.0 |
data.resample('D').ffill # 填充缺失值
# data.resample('D').bfill()
| one | two | three | four | |
|---|---|---|---|---|
| 2020-01-15 | 8 | 3 | 6 | 1 |
| 2020-01-16 | 8 | 3 | 6 | 1 |
| 2020-01-17 | 8 | 3 | 6 | 1 |
| 2020-01-18 | 8 | 3 | 6 | 1 |
| 2020-01-19 | 8 | 3 | 6 | 1 |
| 2020-01-20 | 8 | 3 | 6 | 1 |
| 2020-01-21 | 8 | 3 | 6 | 1 |
| 2020-01-22 | 6 | 5 | 0 | 2 |
也可以仅填充指定的时期数(目的是限制前面观测值的持续使用距离,limit = 2表示前面的观测值只能填充往后的两行数据)
n=np.arange(8).reshape(2,4)
k=np.pad(n,pad_width=((2,3),(3,3)),mode='constant',constant_values=(0))
print(k)
[[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 1 2 3 0 0 0]
[0 0 0 4 5 6 7 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]]
n:代表的是数组
pad_width:代表的是不同维度填充的长度,(2,3)分别代表第一个维度左填充2,右边填充3。(3,3)代表第二个维度左边填充3右边填充3。
第一个维度:指的是第一个括号内的元素
第二个维度:指的是第二个括号内的元素
第n个维度:依次类推
data.resample('D').pad(limit=2)
| one | two | three | four | |
|---|---|---|---|---|
| 2020-01-15 | 8.0 | 3.0 | 6.0 | 1.0 |
| 2020-01-16 | 8.0 | 3.0 | 6.0 | 1.0 |
| 2020-01-17 | 8.0 | 3.0 | 6.0 | 1.0 |
| 2020-01-18 | NaN | NaN | NaN | NaN |
| 2020-01-19 | NaN | NaN | NaN | NaN |
| 2020-01-20 | NaN | NaN | NaN | NaN |
| 2020-01-21 | NaN | NaN | NaN | NaN |
| 2020-01-22 | 6.0 | 5.0 | 0.0 | 2.0 |
5、通过日期进行重采样
对于使用时期索引的数据进行重采样较为简单,先创建一个对象:
df = pd.DataFrame(np.random.randn(24,4))
df.index = pd.period_range('2020-1',periods=24,freq='M')
df.columns = ['one','two','three','four']
df
| one | two | three | four | |
|---|---|---|---|---|
| 2020-01 | -0.979084 | -0.431727 | -0.003613 | 0.239935 |
| 2020-02 | -0.591629 | -0.041868 | -0.042129 | 1.735916 |
| 2020-03 | 0.047618 | -0.651828 | -0.004301 | 0.017937 |
| 2020-04 | -0.097645 | -0.563879 | 0.452829 | -0.630004 |
| 2020-05 | -0.114215 | -0.428281 | 0.409666 | -0.991012 |
| 2020-06 | -0.488310 | 0.475253 | 0.419103 | -0.111489 |
| 2020-07 | -1.828562 | 1.251410 | -1.564868 | 1.072381 |
| 2020-08 | 2.068238 | -0.698950 | 0.959692 | 0.704877 |
| 2020-09 | 0.519954 | -0.189848 | -0.234610 | -0.478327 |
| 2020-10 | -0.335129 | 0.377634 | -1.126909 | 0.589016 |
| 2020-11 | -0.410480 | -0.174261 | -0.921766 | 0.426526 |
| 2020-12 | -0.735885 | 0.582575 | 0.174124 | -1.819708 |
| 2021-01 | 1.502580 | -1.056993 | -0.185758 | 0.873479 |
| 2021-02 | -0.147175 | -0.455576 | 1.358502 | -1.088891 |
| 2021-03 | -0.227551 | 1.256427 | -0.516975 | 0.535406 |
| 2021-04 | 0.530525 | 0.405756 | 1.200586 | 0.259992 |
| 2021-05 | 0.262048 | 0.117184 | 0.737047 | -0.016959 |
| 2021-06 | -1.988128 | 1.584430 | 1.647670 | 0.873219 |
| 2021-07 | -0.902770 | -0.997992 | -0.007074 | -0.014629 |
| 2021-08 | 0.398101 | -1.146586 | -0.390514 | 0.532349 |
| 2021-09 | -1.094471 | 0.131216 | 0.441688 | 0.297797 |
| 2021-10 | -0.236048 | 1.166033 | -1.359992 | 0.419473 |
| 2021-11 | 0.546093 | -0.256319 | -0.672782 | -1.025643 |
| 2021-12 | 1.237619 | -0.527950 | 0.419971 | -0.193061 |
传入’A-DEC’进行降采样(使用年度财政的方式)
df.resample('A-DEC').mean()
| one | two | three | four | |
|---|---|---|---|---|
| 2020 | -0.245427 | -0.041148 | -0.123565 | 0.063004 |
| 2021 | -0.009931 | 0.018302 | 0.222697 | 0.121044 |
传入’A-JUN’进行降采样(使用6月作为财政年度的分割单位)
df.resample('A-JUN').mean()
| one | two | three | four | |
|---|---|---|---|---|
| 2020 | -0.370544 | -0.273722 | 0.205259 | 0.043547 |
| 2021 | -0.065797 | 0.249982 | 0.127228 | 0.160918 |
| 2022 | -0.008579 | -0.271933 | -0.261451 | 0.002714 |
6、通过日期进行升采样
需决定在新频率中,各区间的哪端用于放置原来的值,convention参数默认为
start,可设置为end
annu_df = df.resample('A-DEC').mean()
annu_df
| one | two | three | four | |
|---|---|---|---|---|
| 2020 | -0.245427 | -0.041148 | -0.123565 | 0.063004 |
| 2021 | -0.009931 | 0.018302 | 0.222697 | 0.121044 |
annu_df.resample('Q-DEC').ffill()
| one | two | three | four | |
|---|---|---|---|---|
| 2020Q1 | -0.245427 | -0.041148 | -0.123565 | 0.063004 |
| 2020Q2 | -0.245427 | -0.041148 | -0.123565 | 0.063004 |
| 2020Q3 | -0.245427 | -0.041148 | -0.123565 | 0.063004 |
| 2020Q4 | -0.245427 | -0.041148 | -0.123565 | 0.063004 |
| 2021Q1 | -0.009931 | 0.018302 | 0.222697 | 0.121044 |
| 2021Q2 | -0.009931 | 0.018302 | 0.222697 | 0.121044 |
| 2021Q3 | -0.009931 | 0.018302 | 0.222697 | 0.121044 |
| 2021Q4 | -0.009931 | 0.018302 | 0.222697 | 0.121044 |
索引调整方法
一、调整索引、修改列标签
1、调整索引的两种情况:
- 重新索引
- 设置新的索引
(1)重新索引
在Pandas对象中,其实索引也是一个对象,所以可对其进行修改。
例如:df.index=[‘a’,’b’,’c’]
import pandas as pd
import numpy as np
df = {'one':pd.Series(np.random.randn(3)),'two':pd.Series(np.random.randn(3)),
'three':pd.Series(np.random.rand(3))}
df = pd.DataFrame(df)
df
| one | three | two | |
|---|---|---|---|
| 0 | -0.132205 | 0.479927 | 2.538764 |
| 1 | -0.339174 | 0.945127 | -0.049037 |
| 2 | -0.462124 | 0.210660 | 1.197265 |
#设置索引
df.index=['a','b','c']
df
| one | three | two | |
|---|---|---|---|
| a | -0.132205 | 0.479927 | 2.538764 |
| b | -0.339174 | 0.945127 | -0.049037 |
| c | -0.462124 | 0.210660 | 1.197265 |
(2)设置新的索引
reindex():重新索引并得到一个新的Pandas对象。
且reindex()方法不仅可以重新索引DataFrame,也可以同时实现过滤功能。
new = df.reindex(['b','c','e'])
new
| one | three | two | |
|---|---|---|---|
| b | -0.339174 | 0.945127 | -0.049037 |
| c | -0.462124 | 0.210660 | 1.197265 |
| e | NaN | NaN | NaN |
# reindex()也可以用来调整列的顺序,这时需要设定'columns'=对应的列名;
df.reindex(columns=['three','two','one'])
| three | two | one | |
|---|---|---|---|
| a | 0.479927 | 2.538764 | -0.132205 |
| b | 0.945127 | -0.049037 | -0.339174 |
| c | 0.210660 | 1.197265 | -0.462124 |
(3)使用set_index()可以指定某一列为索引,这在对日期型数据或者是以名称进行区分的数据非常有用
# 若是希望在原来索引的基础之上添加新的变量构成层次化索引,则设置append参数为True;
df.set_index('one',append=True)
| three | two | ||
|---|---|---|---|
| one | |||
| a | -0.132205 | 0.479927 | 2.538764 |
| b | -0.339174 | 0.945127 | -0.049037 |
| c | -0.462124 | 0.210660 | 1.197265 |
df.set_index('one',drop=False)
| one | three | two | |
|---|---|---|---|
| one | |||
| 0.165862 | 0.165862 | 0.092076 | -1.385827 |
| -1.028590 | -1.028590 | 0.097918 | 0.428650 |
| 0.472469 | 0.472469 | 0.856475 | 0.364913 |
2、修改标签
修改索引和列名的标签可以使用rename()方法结合字典、Series或者一个原函数将标签映射为一个新的标签。
(1)关于结合字典
(2)使用函数映射的方式
例:将字符串的大写转换函数传入,对列标签进行修改
df.rename(columns=str.upper)
| ONE | THREE | TWO | |
|---|---|---|---|
| a | -0.132205 | 0.479927 | 2.538764 |
| b | -0.339174 | 0.945127 | -0.049037 |
| c | -0.462124 | 0.210660 | 1.197265 |
例:结合lambda:将所有的列的前2个字符大写,其余小写
df.rename(columns=lambda x:x[:2].upper()+x[2:].lower())
| ONe | THree | TWo | |
|---|---|---|---|
| a | -0.132205 | 0.479927 | 2.538764 |
| b | -0.339174 | 0.945127 | -0.049037 |
| c | -0.462124 | 0.210660 | 1.197265 |
二、创建层次化索引
层次化索引可以基于Series和DataFrame创建更加高维的数据。
也就是说,若有一个DataFrame是一个堆积式的(在一个轴上需要创建不止一个索引),那么此时就需要用到层次化索引,这和Panel有些类似。但是在实际中并不是很常用!
创建一个层次化索引:
data=pd.Series(np.random.randn(5),index=[['a','a','b','b','b'],['a1','a2','b1','b2','b3']])
data
a a1 -0.632830
a2 -0.222871
b b1 1.220479
b2 0.761969
b3 -0.274735
dtype: float64
data.index
MultiIndex(levels=[['a', 'b'], ['a1', 'a2', 'b1', 'b2', 'b3']],
labels=[[0, 0, 1, 1, 1], [0, 1, 2, 3, 4]])
#levels包含了每个级别索引的标签,labels是对每个数据在对应不同levels的位置进行了标记
每个index均有一个属性(名称names),可通过.index.names对索引列的列名进行创建于修改
data.index.names=['first','second']
data
first second
a a1 -0.632830
a2 -0.222871
b b1 1.220479
b2 0.761969
b3 -0.274735
dtype: float64
三、重排级别顺序
重排级别顺序是基于有索引个数>=1的DataFrame。
(1)swaplevel():将columns轴上的索引级别进行互换。
df.swaplevel(0,1,axis=1)
(2)reorder_levels():指定多个级别的顺序
(3)提取数据还是可以使用iloc()与loc()
(4)unstack():若index轴上有多个级别索引的DataFrame,使用该方法将指定级别(level参数)安排在columns上形成一个新的DataFrame
日期与时间数据(介绍时序数据、datetime模块介绍、字符串与时间互换)
一、什么是时间序列?
时间序列(Time Series)是一种重要的结构化数据形式,在多个时间点观察或测量到的任何事物都可以形成一段时间序列,可分为以下两种:
定期的时间序列:数据根据某种规律定期出现(例如:每10秒、每1分)
不定期的时间序列:数据之间并没有固定的时间单位或是单位之间的偏移量
二、时间序列的类型有哪些?
时间序列数据的类型主要取决于具体的应用场景,一般可分为3种:
时间戳(Timestamps):即特定的时刻,如2020年1月1日14时12分34秒
固定时期(Fixed periods):如2020年3月或2020年全年
时间间隔(Interval of time):如2020年8月1日到2020年9月1日
三、时间序列类型的处理是否Pandas中独有?
不是Pandas中独有的,Python的基础库中包含了用于日期(date)和时间(time)数据的数据类型,主要用到的模块有datetime和time。
但是Pandas提供了一组标准的时间序列处理工具和数据算法,如切片、切块、聚合、对定期/不定期的时间序列进行重采样等。
四、datetime模块
datetime模块中的数据类型如下:
类型 说明
date 以公历形式存储日历日期(年、月、日)
time 将时间存储为时、分、秒、毫秒
datetime 存储日期和时间,即date和time的结合
timedelta 两个datetime值之间的差(日、秒、毫秒)
其中:datetime.datetime简称为datetime,是最为常用的数据类型。
例:查看当前的日期与时间(记录到秒),为datetime类型:
from datetime import datetime
now=datetime.now()
now
datetime.datetime(2022, 7, 19, 11, 1, 46, 220415)
#可使用如下方式查看年、月、日、时、分、秒
x = [now.year,now.month,now.day,now.hour,now.minute,now.second]
x
[2022, 7, 19, 11, 1, 46]
两个datetime对象之间的时间差(日、秒、毫秒)为timedelta类型
delta = now - datetime(2022,1,14)
delta
datetime.timedelta(186, 39706, 220415)
#所以可以通过如下方式查看日、秒、毫秒
y = [delta.days,delta.seconds,delta.microseconds]
y
[186, 39706, 220415]
五、字符串和datetime的互换
字符串与datetime之间通常需要进行转换,有如下几种方式:
Python标准库函数:
- 日期—>字符串:str或strftime
- 字符串—>日期:datetime.striptime
第三方库函数:
- dateutil.parser时间解析函数
time模块中字符串与时间的互换
1)日期—–>字符串
例:使用str将日期转换成字符串
stamp = datetime(2022,8,8)
str(stamp)
'2022-08-08 00:00:00'
那么如何对datetime的格式进行更改呢,在这就设计到了对datetime格式的定义:
符号 说明
%Y 4位数的年份
%y 2位数的年份
%m 2位数的月
%d 2位数的日
%H 24小时的时
%I 12小时的时
例:使用strftime将日期转换成字符串,并设置格式
stamp.strftime('%Y-%m-%d')
'2022-08-08'
2)字符串—–>日期
例:使用strptime将字符串转换成日期,需要传入格式
需要注意的是:此处的格式不可随便设置,应该与字符串中的格式一致
value = '2022-1-14'
# datetime.strptime(value,'%y-%m-%d') #此时以下将会报错
datetime.strptime(value,'%Y-%m-%d')
datetime.datetime(2022, 1, 14, 0, 0)
values = ['2022-05-23','2028-04-02']
[datetime.strptime(value,'%Y-%m-%d') for vlaue in values ]
[datetime.datetime(2022, 1, 14, 0, 0), datetime.datetime(2022, 1, 14, 0, 0)]
时区处理(UTC查看、获取、时区意识型TimeStamp对象、本地化与转换、计算)
通常选择使用协调世界时(UTC,又称世界统一时间、世界标准时间、国际协调时间)来处理时间序列。
时区是以UTC偏移量的形式表示的。
在Python中,时区信息来自第三方库pytz,Pandas包装了pytz功能。时区名可以在文档中找到,也可以用交互的方式查看。
(1)查看时区
pytz有all_timezones、common_timezones这两个属性来查看有哪些时区;
import pytz
len(pytz.common_timezones)
439
pytz.common_timezones[:5]
['Africa/Abidjan',
'Africa/Accra',
'Africa/Addis_Ababa',
'Africa/Algiers',
'Africa/Asmara']
pytz.common_timezones[-5:]
['US/Eastern', 'US/Hawaii', 'US/Mountain', 'US/Pacific', 'UTC']
len(pytz.all_timezones)
593
pytz.all_timezones[-5:]
['UTC', 'Universal', 'W-SU', 'WET', 'Zulu']
(2)获取时区对象
pytz有timezone属性获取时区对象
tz = pytz.timezone('Asia/Shanghai')
tz
<DstTzInfo 'Asia/Shanghai' LMT+8:06:00 STD>
(3)查看时间序列的时区
Pandas中的时间序列默认是naive时区,即没有时区。用index.tz方法查看时间序列的时区
import pandas as pd
import numpy as np
rng = pd.date_range('2022/8/1',periods=5,freq='D')
ts=pd.Series(np.random.randint(0,10,5),index=rng)
ts
2022-08-01 3
2022-08-02 8
2022-08-03 4
2022-08-04 8
2022-08-05 7
Freq: D, dtype: int32
print(ts.index.tz)
None
# 通过参数tz可以设置时区
rng2 = pd.date_range('2022/8/1',periods=5,freq='D',tz='UTC')
ts2 = pd.Series(np.random.randint(1,10,len(rng2)),index = rng2)
ts2
2022-08-01 00:00:00+00:00 7
2022-08-02 00:00:00+00:00 9
2022-08-03 00:00:00+00:00 7
2022-08-04 00:00:00+00:00 8
2022-08-05 00:00:00+00:00 1
Freq: D, dtype: int32
print(ts2.index.tz)
UTC
(4)本地化和转换
时间序列若需要和转化,必须先使用tz_localize进行时区本地化,再通过tz_convert()转换成别的时区
#先进行本地化转换到别的地区
ts_utc = ts.tz_localize('UTC')
ts_utc.index
DatetimeIndex(['2022-08-01', '2022-08-02', '2022-08-03', '2022-08-04',
'2022-08-05'],
dtype='datetime64[ns, UTC]', freq='D')
#再转换到别的时区
ts_utc.tz_convert('US/Eastern')
2022-07-31 20:00:00-04:00 3
2022-08-01 20:00:00-04:00 8
2022-08-02 20:00:00-04:00 4
2022-08-03 20:00:00-04:00 8
2022-08-04 20:00:00-04:00 7
Freq: D, dtype: int32
(5)操作时区意识型TimeStamp对象
与时间序列和日期范围一样,时间戳对象也能从naive本地化为时区意识型(time zone-aware),并从一个时区转换到另一个时区
例:创建一个时间戳本地化到世界标准时间UTC,并将时区转换为’US/Eastern’
stamp = pd.Timestamp('2022-8-1 18:23:34')
stamp_utc = stamp.tz_localize('UTC')
stamp_utc
Timestamp('2022-08-01 18:23:34+0000', tz='UTC')
stamp_utc_convert = stamp_utc.tz_convert('US/Eastern')
stamp_utc_convert
Timestamp('2022-08-01 14:23:34-0400', tz='US/Eastern')
注意:时区意识型对象在内部保存了一个UTC时间戳,其值在时区转换过程中是不是发生改变的,是从1970年1月1日算起的纳秒数
如:stamp_utc和stamp_utc_convert的值是一样的
stamp_utc_convert.value==stamp_utc.value
True
6)不同时区之间的计算
当两个时间序列的时期不同,若需要将其合并,最后的结果将会是UTC
# rng = pd.date_range('2022/8/1',periods=5,freq='D')
rng = pd.date_range('2022/8/1 10:30',periods=5,freq='D')
ts = pd.Series(np.random.randint(1,10,len(rng)),index = rng)
ts
2022-08-01 10:30:00 9
2022-08-02 10:30:00 4
2022-08-03 10:30:00 5
2022-08-04 10:30:00 5
2022-08-05 10:30:00 1
Freq: D, dtype: int32
ts1 = ts[:2].tz_localize('Europe/Zurich')
ts2 = ts[2:4].tz_localize('US/Arizona')
ts1.index
DatetimeIndex(['2022-08-01 10:30:00+02:00', '2022-08-02 10:30:00+02:00'], dtype='datetime64[ns, Europe/Zurich]', freq='D')
result = ts1 + ts2
result
2022-08-01 08:30:00+00:00 NaN
2022-08-02 08:30:00+00:00 NaN
2022-08-03 17:30:00+00:00 NaN
2022-08-04 17:30:00+00:00 NaN
dtype: float64
result.index
DatetimeIndex(['2022-08-01 08:30:00+00:00', '2022-08-02 08:30:00+00:00',
'2022-08-03 17:30:00+00:00', '2022-08-04 17:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq=None)
日期(Period、PeriodIndex、asfreq、财政年度)及算数运算(to_timestamp()、to_period())
一、时期
1、时期的创建
时期(Period)表示的是时间区间,如数日、数月、数季、数年等。时期的创建需要一个字符或整数以及一个freq参数。
注意:其中freq参数可以参考日期的基础频率表
例:创建一个从20220101到20221231的时期
import pandas as pd
p = pd.Period(2022,freq = 'A-DEC')
p
Period('2022', 'A-DEC')
2、Period对象如何实现位移?
答:加上或减去一个整数
p+10
Period('2032', 'A-DEC')
3、相同频率的Period对象
若两个Period对象由相同的频率,那么这两个Period对象的差就是两个时间段的单位数量;
pd.Period(2030,freq='A-DEC')-p
8
4、PeriodIndex
period_range()函数用于创建规则的时间范围,生成PeriodIndex类型数据;
来看看其用法与创建规则的日期范围date_range()的区别:
pd.period_range('2022-01-01','2022-09-01',freq='2M')
pd.date_range('2022-01-01','2022-09-01',freq='2M')
DatetimeIndex(['2022-01-31', '2022-03-31', '2022-05-31', '2022-07-31'], dtype='datetime64[ns]', freq='2M')
从上述例子可以看到,PeriodIndex类型数据的元素类型是period[2M],而DatetimeIndex类型数据的元素类型是datetime64[ns]。
只要PeriodIndex类保存了一组,就可以在任何Pandas数据结构中被用作轴索引
s = pd.Series(np.random.randint(0,10,4))
s.index = pd.period_range('202001','202004',freq='M')
s
2020-01 1
2020-02 0
2020-03 3
2020-04 1
Freq: M, dtype: int32
# PeriodIndex类的构造还允许直接使用一组字符串
values = ['2018Q1','2019Q2','2020Q3']
index = pd.PeriodIndex(values,freq = 'Q-DEC')
index
PeriodIndex(['2018Q1', '2019Q2', '2020Q3'], dtype='period[Q-DEC]', freq='Q-DEC')
5、通过asfreq频率转换日期
Period对象和PeriodIndex对象都可以通过asfreq方法被转换成别的频率;
(1)参数how:注意start和end
例:将一个年度时期转换为当年年初或年末的月度时期(以12月结束的财政年度)
p = pd.Period(2022,freq = 'A-DEC')
p.asfreq('M',how = 'start')
Period('2022-01', 'M')
p.asfreq('M',how = 'end')
Period('2022-12', 'M')

例:不以12月结束的财政年度,若是以6月结束的财政年度,那么年初、年末的月度时期分别为2006年7月、2007年6月
p = pd.Period(2007,freq = 'A-JUN')
p.asfreq('M',how = 'start')
Period('2006-07', 'M')
p.asfreq('M',how = 'end')
Period('2007-06', 'M')

(2)高频率转换为低频率
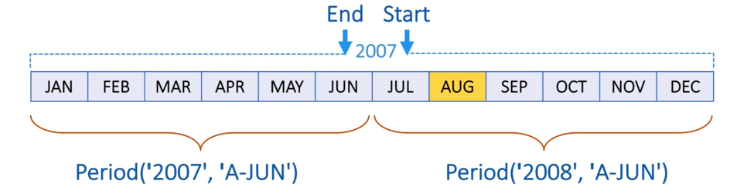
例:将2007年8月的频率转换为’A-JUN’后,月份 2007年8月将属于2008年财政年度(年相较于月,年为低频率,月为高频率,一年12个月)
以asfreq中为准
p = pd.Period('2007-08','M')
p+1
Period('2007-09', 'M')
p.asfreq('A-JUN')
Period('2008', 'A-JUN')
p.asfreq('A-JUN')+1
Period('2009', 'A-JUN')
(3)时间序列频率转换
PeriodIndex和时间序列的频率转换方法一致
rng = pd.period_range('2015','2018',freq = 'A-DEC')
ts = pd.Series(np.random.randint(0,10,4),index = rng)
ts
2015 3
2016 1
2017 1
2018 6
Freq: A-DEC, dtype: int32
ts.asfreq('M',how = 'start')
2015-01 3
2016-01 1
2017-01 1
2018-01 6
Freq: M, dtype: int32
ts.asfreq('M',how = 'end')
2015-12 3
2016-12 1
2017-12 1
2018-12 6
Freq: M, dtype: int32
ts.asfreq('Q-JAN',how = 'start')
2015Q4 3
2016Q4 1
2017Q4 1
2018Q4 6
Freq: Q-JAN, dtype: int32
(4)季度性频率
Pandas支持12种可能的季度型频率,即从Q-JAN到Q-DEC,下表以2012年的Q-DEC、Q-SEP、Q-JAN为例
即季度型频率freq设置为谁,谁就是Q4,因为其含义本就表示财政年末
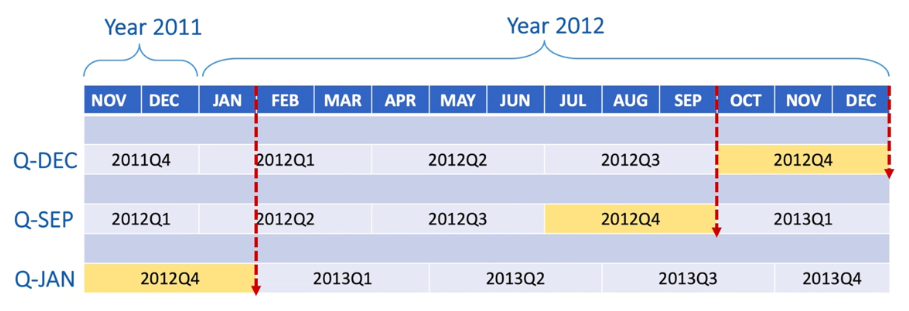
#在以1月结束的财政年中,2012Q4是从2011年11月到2012年1月
p = pd.Period('2012Q4',freq = 'Q-JAN')
p
Period('2012Q4', 'Q-JAN')
p.asfreq('D',how = 'start')
Period('2011-11-01', 'D')
p.asfreq('D',how = 'end')
Period('2012-01-31', 'D')
p.asfreq('M',how = 'start')
Period('2011-11', 'M')
p.asfreq('B',how = 'start')
Period('2011-11-01', 'B')
p.asfreq('B',how = 'end')
Period('2012-01-31', 'B')
二、时期之间的算数运算
例:需要获取时期p的倒数第二个工作日下午4点的时间戳
步骤1:使用第一个asfreq将时期p转换成日期型频率,得到p的倒数第二个工作日的日期
步骤2:使用第二个asfreq将日期型频率转换成时型频率,得到p的倒数第二个工作日的时间
步骤3:将时型频率转换成时间戳
p
Period('2012Q4', 'Q-JAN')
#步骤1
p_next = p.asfreq('B',how = 'end')-1
p_next
Period('2012-01-30', 'B')
#步骤2
p4_p_next = p_next.asfreq('H',how = 'start')+16
p4_p_next
Period('2012-01-30 16:00', 'H')
#步骤3
p4_p_next.to_timestamp()
Timestamp('2012-01-30 16:00:00')
时间戳和日期之间的转换
转为时间戳:to_timestamp()
转为日期:to_period()
例:通过数组创建PeriodIndex(年和季度存放于不同的列中,将其合并并设为索引)
data = pd.DataFrame({'year':[2019,2019,2019,2019,2020,2020],'quarter':[1,2,3,4,1,2]})
data['number'] = np.random.randint(0,100,6)
data
| quarter | year | number | |
|---|---|---|---|
| 0 | 1 | 2019 | 47 |
| 1 | 2 | 2019 | 62 |
| 2 | 3 | 2019 | 14 |
| 3 | 4 | 2019 | 74 |
| 4 | 1 | 2020 | 45 |
| 5 | 2 | 2020 | 67 |
index = pd.PeriodIndex(year = data['year'],quarter = data['quarter'],freq = 'Q-DEC')
index
PeriodIndex(['2019Q1', '2019Q2', '2019Q3', '2019Q4', '2020Q1', '2020Q2'], dtype='period[Q-DEC]', freq='Q-DEC')
data.index = index
data.drop(['year','quarter'],axis=1,inplace = True)
data
| number | |
|---|---|
| 2019Q1 | 47 |
| 2019Q2 | 62 |
| 2019Q3 | 14 |
| 2019Q4 | 74 |
| 2020Q1 | 45 |
| 2020Q2 | 67 |
时间序列处理的基础(时序数据类型、筛选、子集提取、重复时间索引操作)
Pandas中最为基础的时间序列类型就是以时间戳(通过以Python字符串或datetime对象表示)为索引的Series;
import pandas as pd
import numpy as np
dates = ['2020-8-1','2020-8-2','2020-8-3','2020-8-4','2020-8-5']
ts = pd.Series(np.random.randint(0,10,5))
ts.index=pd.to_datetime(dates)
ts
2020-08-01 9
2020-08-02 5
2020-08-03 9
2020-08-04 2
2020-08-05 3
dtype: int32
二、Pandas中时间序列数据的筛选
关于日期数据的筛选与python基本库中的切片方式一致;
#选取前3条数据
ts[:3]
2020-08-01 9
2020-08-02 5
2020-08-03 9
dtype: int32
#从前往后(正序),每个两个元素取数据
ts[::2]
2020-08-01 9
2020-08-03 9
2020-08-05 3
dtype: int32
Pandas不同索引之间的时间序列之前的算数运算会自动按日期进行对齐(其实只是Series的特征罢了)
ts+ts[::2]
2020-08-01 18.0
2020-08-02 NaN
2020-08-03 18.0
2020-08-04 NaN
2020-08-05 6.0
dtype: float64
三、Pandas中时间序列数据如何提取子集
(1)通过index[]选取子集
ts.index
len(ts.index)
5
ts.index[2]
Timestamp('2020-08-03 00:00:00')
ts[ts.index[2]]
9
(2)通过字符串选取子集,在这需要注意的是:传入的字符串需要能被解析成日期;
也可以传入只包含年或年月的字符串,选取该范围内的子集;
ts['2020-8-1']
ts['2020/8/1']
9
ts['8/1/2020']
9
ts['2020-8']
2020-08-01 9
2020-08-02 5
2020-08-03 9
2020-08-04 2
2020-08-05 3
dtype: int32
(3)通过truncate方法选取子集
truncate()常用参数有after和before,传入参数后,after之后或before之前的数据将全部被删除;
ts.truncate(after='2020-8-3')
2020-08-01 9
2020-08-02 5
2020-08-03 9
dtype: int32
ts.truncate(before='2020-8-3')
2020-08-03 9
2020-08-04 2
2020-08-05 3
dtype: int32
四、带有重复索引的时间序列的操作
在某些应用场景中,通常会存在一个时间点上有多个观测数据的情况,对于带有重复索引的时间序列,一般情况下使用如下两种方法进行操作:
index.is_unique检查索引日期是否唯一
使用groupby()对数据进行分组聚合
dup_ts = pd.Series(np.random.randint(0,5,5))
dup_ts.index=pd.to_datetime(['2020-8-1','2020-8-2','2020-8-2','2020-8-2','2020-8-3'])
dup_ts
2020-08-01 2
2020-08-02 2
2020-08-02 1
2020-08-02 3
2020-08-03 0
dtype: int32
dup_ts['2020-8-2']
2020-08-02 2
2020-08-02 1
2020-08-02 3
dtype: int32
#查看时间序列的索引是否唯一
dup_ts.index.is_unique
False
#使用groupby进行分组聚合
dup_ts.groupby(level=0).sum()
2020-08-01 2
2020-08-02 6
2020-08-03 0
dtype: int32
dup_ts.groupby(level=0).count()
2020-08-01 1
2020-08-02 3
2020-08-03 1
dtype: int64
若有一个csv文件,在数据导入是可以通过参数实现将字符串类型的时间设为索引,设定index_col为0即以数据中第一列为索引,设定parse_dates为True,会把索引识别为时间数据类型。
data = pd.read_csv(‘***.csv’,index_col=0,parse_dates=True)
时序数据处理(日期范围pd.date_range()、频率(基础频率表)及移动(shift()、rollforward()、rollback()))
一、生成日期范围的时序数据
pd.date_range()可用于生成指定长度的日期索引,默认产生按天计算的时间点(即日期范围)。其参数可以是:
起始结束日期
或者是仅有一个起始或结束日期,加上一个时间段参数
以下三种方法结果一致:
pd.date_range(‘20200801’,’20200810’)
pd.date_range(start=’20200801’,periods=10)
pd.date_range(end=’20200810’,periods=10)
结果:
DatetimeIndex([‘2020-08-01’, ‘2020-08-02’, ‘2020-08-03’, ‘2020-08-04’,
‘2020-08-05’, ‘2020-08-06’, ‘2020-08-07’, ‘2020-08-08’,
‘2020-08-09’, ‘2020-08-10’],
dtype=’datetime64[ns]’, freq=’D’)
注意:此处的freq参数表示时间序列数据的频率,其值为D,表示是以天为频率;
所以,若想生成一个特殊频率的日期索引,若一个由每月最后一个工作日组成的日期索引,直接加上参数freq=’BM’(BM表示business end of month)
import pandas as pd
import numpy as np
pd.date_range('2020-01-01','2020-12-31',freq='BM')
DatetimeIndex(['2020-01-31', '2020-02-28', '2020-03-31', '2020-04-30',
'2020-05-29', '2020-06-30', '2020-07-31', '2020-08-31',
'2020-09-30', '2020-10-30', '2020-11-30', '2020-12-31'],
dtype='datetime64[ns]', freq='BM')
二、日期频率
pandas中的频率是由一个基础频率和一个乘数组成。基础频率通常以一个字符串别名表示,如’M’,’H’。
date_range()参数freq的取值说明
基础频率表
别名 偏移量类型 说明
D Day 每日历日
B BusinessDay 每工作日
H Hour 每小时
T或min Minute 每分
M MonthEnd 每月最后一个日历日
BM BusinessMonthEnd 每月最后一个工作日
WOM-1MON WeekOfMonth 产生每月第一、第二、第四周的星期几,如WOM-3FRI表示每月第3个周五
Q-JAN QuarterEnd 对于指定月份(JAN、FEB、MAR…DEC)结束的年度,每季度最后一个月的最后一个日历日
A-JAN YearEnd 对于指定年份的最后一个日历日
例:从2022年1月至2022年3月以’3M’的频率生成一个时间范围
pd.date_range('2022-01-01','2022-12-31',freq='3M')
DatetimeIndex(['2022-01-31', '2022-04-30', '2022-07-31', '2022-10-31'], dtype='datetime64[ns]', freq='3M')
pd.date_range('2022-01-01','2022-12-31',freq='WOM-3FRI')
DatetimeIndex(['2022-01-21', '2022-02-18', '2022-03-18', '2022-04-15',
'2022-05-20', '2022-06-17', '2022-07-15', '2022-08-19',
'2022-09-16', '2022-10-21', '2022-11-18', '2022-12-16'],
dtype='datetime64[ns]', freq='WOM-3FRI')
pd.date_range('2020-01-01',periods=3,freq='2H30T') #两小时三十分
DatetimeIndex(['2020-01-01 00:00:00', '2020-01-01 02:30:00',
'2020-01-01 05:00:00'],
dtype='datetime64[ns]', freq='150T')
对于每个基础频率,都有一个日期偏移量(date offset)对象与之对应。可以通过实例化日期偏移量来创建某种频率:
from pandas.tseries.offsets import Hour,Minute
hour = Hour()
hour
<Hour>
four_hours = Hour(4)
four_hours
<4 * Hours>
大部分偏移量对象可以通过加法进行连接:
Hour(3)+Minute(20)
<200 * Minutes>
有些频率所描述的时间点并不是均匀分隔的。例如’M’和’BM’就取决于每月的天数,对于后者,还要考虑月末是否是周末,将这些成为锚点偏移量。
三、移动(超前或之后)数据
(1)移动(Shifting)指的是沿着时间轴将数据向前或向后移动,保持索引不变。
thift()方法默认表示索引不变数据后移;若提供freq参数,则此时将移动index,数据将保持不变
#创建一个时序数据
ts = pd.Series(np.random.randint(0,10,5))
ts.index = pd.date_range('2022-1-1',periods=5,freq='M')
ts
2022-01-31 2
2022-02-28 4
2022-03-31 9
2022-04-30 4
2022-05-31 6
Freq: M, dtype: int32
#索引不变,数据向后移2个单位
ts.shift(2)
2022-01-31 NaN
2022-02-28 NaN
2022-03-31 2.0
2022-04-30 4.0
2022-05-31 9.0
Freq: M, dtype: float64
#索引不变,数据向前移2个单位
ts.shift(-2)
2022-01-31 9.0
2022-02-28 4.0
2022-03-31 6.0
2022-04-30 NaN
2022-05-31 NaN
Freq: M, dtype: float64
#将时间索引向后移2个月,数据保持不变
ts.shift(2,freq='M')
2022-03-31 2
2022-04-30 4
2022-05-31 9
2022-06-30 4
2022-07-31 6
Freq: M, dtype: int32
#将时间索引向前移2个月,数据保持不变
ts.shift(-2,freq='M')
2021-11-30 2
2021-12-31 4
2022-01-31 9
2022-02-28 4
2022-03-31 6
Freq: M, dtype: int32
(2)如何通过偏移量对日期进行位移?
在时间后直接加上一个实例化的日期偏移量即可。
from pandas.tseries.offsets import Day,MonthEnd
from datetime import datetime
t = datetime(2022,8,8)
t + 10*Day()
Timestamp('2022-08-18 00:00:00')
#第一次位移量没有一个月那么长,则位移就在当月,所以此时进行2个位移的结果是9月
t + 2*MonthEnd()
Timestamp('2022-09-30 00:00:00')
(3)结合锚点偏移量,使用rollforward()和rollback()方法,可以将日期向前或向后滚动
from pandas.tseries.offsets import MonthEnd,YearEnd,QuarterEnd
offset = MonthEnd()
t
datetime.datetime(2022, 8, 8, 0, 0)
#向前滚动
offset.rollback(t)
Timestamp('2022-07-31 00:00:00')
offset1 = YearEnd()
offset1.rollback(t)
Timestamp('2021-12-31 00:00:00')
offset1.rollforward(t)
Timestamp('2022-12-31 00:00:00')
offset2 = QuarterEnd()
offset2.rollforward(t)
Timestamp('2022-09-30 00:00:00')
四、例子:若有以下时间序列,如何在每月月末显示该月数据的均值
ts = pd.Series(np.random.randint(0,10,10))
ts.index = pd.date_range(start='2020-1-15',periods=10,freq='10D')
ts
2020-01-15 2
2020-01-25 1
2020-02-04 8
2020-02-14 2
2020-02-24 0
2020-03-05 5
2020-03-15 1
2020-03-25 2
2020-04-04 6
2020-04-14 2
Freq: 10D, dtype: int32
解法步骤:
先将时间序列使用rollforward()向前滚动,这样将日期索引都设置为当前月的最后一天;
使用groupby()对时间索引进行分组聚合,求其均值
offset = MonthEnd()
#方法一:使用列表推导式将时间序列向后滚动至当前月的最后一天,再将生成的列表转换成DatetimeIndex
ts.index = pd.to_datetime([offset.rollforward(index) for index in ts.index])
ts
2020-01-31 2
2020-01-31 1
2020-02-29 8
2020-02-29 2
2020-02-29 0
2020-03-31 5
2020-03-31 1
2020-03-31 2
2020-04-30 6
2020-04-30 2
dtype: int32
#使用Groupby()聚合分组
ts.groupby(ts.index).mean()
2020-01-31 1.500000
2020-02-29 3.333333
2020-03-31 2.666667
2020-04-30 4.000000
dtype: float64
#方法二:以下结果与上述结果一致
ts.groupby(offset.rollforward).mean()
2020-01-31 1.500000
2020-02-29 3.333333
2020-03-31 2.666667
2020-04-30 4.000000
dtype: float64
方法一改变了ts,方法二没有;若在使用过程中,若想使用方法一又不想改变ts的值,可以先复制一个ts,然后对复制后的ts进行操作即可。
数据转换(df.map()、df.replace())
在数据分析中,根据需求,有时候需要将一些数据进行转换,而在Pandas中,实现数据转换的常用方法有:
利用函数或是映射
可以将自己定义的或者是其他包提供的函数用在Pandas对象上实现批量修改。
applymap和map实例方法
import pandas as pd
import numpy as np
df = pd.DataFrame({'number_project':['2','5','7','3','6','4'],
'left':[1,1,0,0,0,1],
'salary':['low','medium','medium','low','low','medium'],
})
一、map()、replace()
(1)使用函数。例:将salary列的数据转换成每个单词的字母大写:
df['salary'].map(str.title)[:5]
0 Low
1 Medium
2 Medium
3 Low
4 Low
Name: salary, dtype: object
(2)使用映射关系的字典。例:对于left,生成一个指标标量indicator。若为‘YES’,表示left=1,若为‘NO’,表示left=0(一般在数据处理时是将字符处理成0,1…n,在此时为了便于理解,故如此举例)。
mapper = {0:'NO',1:'YES'}
df['left'] = df['left'].map(mapper)
df
| left | number_project | salary | |
|---|---|---|---|
| 0 | YES | 2 | low |
| 1 | YES | 5 | medium |
| 2 | NO | 7 | medium |
| 3 | NO | 3 | low |
| 4 | NO | 6 | low |
| 5 | YES | 4 | medium |
注意:使用映射关系的字典map()必须考虑到所有的值,若没有,那么没有映射关系的值将会为NaN,如下例子:
s = pd.Series(['A','B','C'])
s.map({'A':10,'B':100})
0 10.0
1 100.0
2 NaN
dtype: float64
(3)重命名索引—->通过map方法可以对行索引或是列名的Index对象进行修改(行索引和列明都是Index对象)
df.columns
df.columns.map(str.upper)
Index(['LEFT', 'NUMBER_PROJECT', 'SALARY'], dtype='object')
(4)使用映射,若需要将数据按照一定的映射关系进行替换,使用replace()。多个值的替换可以用列表,少数的值可以用包含映射关系的字典字典。
例:将number_project的值2、3、4设置为less,5、6、7设置为More。
df['number_project'] = df['number_project'].replace([2,3,4,5,6,7],['Less','Less','Less','More','More','More'])
df
| left | number_project | salary | |
|---|---|---|---|
| 0 | YES | 2 | low |
| 1 | YES | 5 | medium |
| 2 | NO | 7 | medium |
| 3 | NO | 3 | low |
| 4 | NO | 6 | low |
| 5 | YES | 4 | medium |
df1 = pd.DataFrame({'user':[2,5,7,3,6,4],
'term':['36 months','46 months','56 months','33 months','36 months','32 months'],
'int_rate':['13.66%','11.99%','15.59%','11.44%','13.66%','13.66%'],
'grade':['C','B','A','D','C','B'],
'loan_status':['Fully Paid','Charged Off','Fully Paid','Fully Paid','Fully Paid','Charged Off'],
})
1)loan_status状态为”Charged Off”的贷款有违约风险,视为不良贷款,将其值标记为1,其他贷款标记为0。我们使用replace()进行值替换
df1['loan_status']=df1['loan_status'].replace(['Fully Paid','Charged Off'],[0,1])
df1
| grade | int_rate | loan_status | term | user | |
|---|---|---|---|---|---|
| 0 | C | 13.66% | 0 | 36 months | 2 |
| 1 | B | 11.99% | 1 | 46 months | 5 |
| 2 | A | 15.59% | 0 | 56 months | 7 |
| 3 | D | 11.44% | 0 | 33 months | 3 |
| 4 | C | 13.66% | 0 | 36 months | 6 |
| 5 | B | 13.66% | 1 | 32 months | 4 |
2)replace()也可以同时指定不同变量的不同值替换为相同新值
df1.replace(to_replace={'loan_status':0,'grade':'B'},value='Good')
| grade | int_rate | loan_status | term | user | |
|---|---|---|---|---|---|
| 0 | C | 13.66% | Good | 36 months | 2 |
| 1 | Good | 11.99% | 1 | 46 months | 5 |
| 2 | A | 15.59% | Good | 56 months | 7 |
| 3 | D | 11.44% | Good | 33 months | 3 |
| 4 | C | 13.66% | Good | 36 months | 6 |
| 5 | Good | 13.66% | 1 | 32 months | 4 |
说明:to_replace指需要替换的值,value指要替换成的新值。replace作为数值替换的方法,适用范围非常之广,可以实现多种操作。
3)也可以使用正则进行替换,设置regex=True即可,代表to_replace部分输入的是正则表达式部分
例:将D开头的全部内容替换成Bad
df1.replace(to_replace='D+.*$',value='Bad',regex=True)
| grade | int_rate | loan_status | term | user | |
|---|---|---|---|---|---|
| 0 | C | 13.66% | 0 | 36 months | 2 |
| 1 | B | 11.99% | 1 | 46 months | 5 |
| 2 | A | 15.59% | 0 | 56 months | 7 |
| 3 | Bad | 11.44% | 0 | 33 months | 3 |
| 4 | C | 13.66% | 0 | 36 months | 6 |
| 5 | B | 13.66% | 1 | 32 months | 4 |
数据转换(哑变量编码pd.get_dummies())
哑变量编码
1、什么叫做哑变量?
将类别型特征转化“哑变量矩阵”或是“指标矩阵”,让类别特征转换成数值特征的过程。相当与标签化和OneHOt编码
2、哑变量将派生出那些特征?
哑变量将会从一个含有k个不同值的特征,派生出k-1个二元特征。因为在建模过程中,有k类的分类变量只需要k-1个变量将其描述,若使用k个变量将出现完全共线性的问题。
3、如何实现哑变量编码?
使用get_dummies()函数,指定prefix参数的值来设置前缀;
例:(1)使用get_dummies()对salary进行转换。
由于原始数据中有一条salary的值为‘nme’的数据,先将该条数据进行删除,在对salsry进行哑变量编码:
import pandas as pd
import numpy as np
data=pd.DataFrame({'number_project':[2,5,7,5,2],
'left':[1,1,1,1,1],
'salary':['low','medium','hogh','low','low'],
})
#删掉salary为‘nme’那条记录
data = data[~data['salary'].isin(['nme'])]
data.tail()
| left | number_project | salary | |
|---|---|---|---|
| 0 | 1 | 2 | low |
| 1 | 1 | 5 | medium |
| 2 | 1 | 7 | hogh |
| 3 | 1 | 5 | low |
| 4 | 1 | 2 | low |
pd.get_dummies(data['salary'])[:5]
| hogh | low | medium | |
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 |
| 2 | 1 | 0 | 0 |
| 3 | 0 | 1 | 0 |
| 4 | 0 | 1 | 0 |
#通过prefix设置前缀
dummies=pd.get_dummies(data['salary'],prefix = 'salary')
dummies[:5]
| salary_hogh | salary_low | salary_medium | |
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 |
| 2 | 1 | 0 | 0 |
| 3 | 0 | 1 | 0 |
| 4 | 0 | 1 | 0 |
2)使用df.join()或pd.concat()将新的哑变量编码数据与原本未编码的数据进行合并
#展示全部的列
pd.set_option('display.max_columns',None)
#合并数据---df.join()
newdata = data[['number_project','left']].join(dummies)
newdata.head()
| number_project | left | salary_hogh | salary_low | salary_medium | |
|---|---|---|---|---|---|
| 0 | 2 | 1 | 0 | 1 | 0 |
| 1 | 5 | 1 | 0 | 0 | 1 |
| 2 | 7 | 1 | 1 | 0 | 0 |
| 3 | 5 | 1 | 0 | 1 | 0 |
| 4 | 2 | 1 | 0 | 1 | 0 |
#合并数据---pd.concat()
newdata1 = pd.concat([data[['number_project','left']],dummies],axis=1)
newdata1[:5]
| number_project | left | salary_hogh | salary_low | salary_medium | |
|---|---|---|---|---|---|
| 0 | 2 | 1 | 0 | 1 | 0 |
| 1 | 5 | 1 | 0 | 0 | 1 |
| 2 | 7 | 1 | 1 | 0 | 0 |
| 3 | 5 | 1 | 0 | 1 | 0 |
| 4 | 2 | 1 | 0 | 1 | 0 |
(3)若需要对DataFrame中所有的元素均进行哑变量变化,则
pd.get_dummies(data)
(4)若仅需要对某几个特征进行编码,可以用columns进行指定要编码的特征;
pd.get_dummies(data,columns=[‘salary’])
(5)通过drop_first = True将第一个编码特征丢掉;
pd.get_dummies(data,columns=['salary'],drop_first = True)[:5]
| left | number_project | salary_low | salary_medium | |
|---|---|---|---|---|
| 0 | 1 | 2 | 1 | 0 |
| 1 | 1 | 5 | 0 | 1 |
| 2 | 1 | 7 | 0 | 0 |
| 3 | 1 | 5 | 1 | 0 |
| 4 | 1 | 2 | 1 | 0 |
数据转换(文本数据规整)
Pandas对于字符串和文本处理通常是由一些内置的字符串方法指定,一般语法格式为:series.str.method。其中,str.method被称为矢量化的字符串方法,包括str.upper()、str.lower()、str.split()等一系列字符串的内置方法,还可以结合正则化式进行处理。
(1)矢量化的字符串方法将对Series或者Index中的每个元素都进行相同的处理;
说明:缺失值不做任何处理
s = pd.Series(['ADJruK','hjuQ',np.nan,'hj'])
s
0 ADJruK
1 hjuQ
2 NaN
3 hj
dtype: object
s.str.upper()
0 ADJRUK
1 HJUQ
2 NaN
3 HJ
dtype: object
(2)对于Index对象也可以使用矢量化字符串的处理方式
df = pd.DataFrame(np.random.randint(10,size=(2,3)),columns=['Jack Joe','BOB Marly','sid Jane'])
df
| Jack Joe | BOB Marly | sid Jane | |
|---|---|---|---|
| 0 | 8 | 1 | 4 |
| 1 | 1 | 8 | 3 |
#将所有列名转化为小写
df.columns = df.columns.str.lower()
df
| jack joe | bob marly | sid jane | |
|---|---|---|---|
| 0 | 8 | 1 | 4 |
| 1 | 1 | 8 | 3 |
(3)链式法则(chain rules):将多个数据规整写在一行代码中;
#将所有列名转化为小写,再使用下划线代替空格
df.columns = df.columns.str.lower().str.replace(' ','_')
df
| jack_joe | bob_marly | sid_jane | |
|---|---|---|---|
| 0 | 8 | 1 | 4 |
| 1 | 1 | 8 | 3 |
(4)分割元素:str.split()可以将一个Series对象规整为包含多个Series对象或DataFrame对象;
例:需求为提取每个元素的姓名—使用str.get方法或世界在str上进行索引
ss = pd.Series(['name1 sex1 age1','name2 sex2 age2','name3 sex3 age3'])
ss
0 name1 sex1 age1
1 name2 sex2 age2
2 name3 sex3 age3
dtype: object
new_ss = ss.str.split(" ")
new_ss
# type(new_ss)|
0 [name1, sex1, age1]
1 [name2, sex2, age2]
2 [name3, sex3, age3]
dtype: object
new_ss[0]
['name1', 'sex1', 'age1']
#方法一:直接在str属性上使用索引(即str[]),即可提取每个样本的姓名
new_ss.str[0]
0 name1
1 name2
2 name3
dtype: object
若需要将分隔开的元素规整成一个DataFrame,可以使用expand参数将分隔开的各个部分展开
ss.str.split(" ",expand = True)
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | name1 | sex1 | age1 |
| 1 | name2 | sex2 | age2 |
| 2 | name3 | sex3 | age3 |
(5)结合正则表达式
Series.str属性结合正则表达式可以匹配一定模式的字符的换的提取、判断、替换等操作。
这些矢量化的字符串包括str.contains(查看是否包含指定的信息)、str.findall(提取指定的信息)、str.match、str.relpace(替换)和str.extract(指定捕获组以提取某信息)等等
以爬取的“58同城网重庆市南岸区二手房数据中的楼层数(floors)”为例。
df=pd.DataFrame({'floor':['中层(共16层)','中层(共31层)','中层(共33层)','中层(共16层)','中层(共28层)'],})
df.head()
| floor | |
|---|---|
| 0 | 中层(共16层) |
| 1 | 中层(共31层) |
| 2 | 中层(共33层) |
| 3 | 中层(共16层) |
| 4 | 中层(共28层) |
使用str.contains()找到其中包含数字的元素
df['floor'].str.contains(r'\d')[:5]
0 True
1 True
2 True
3 True
4 True
Name: floor, dtype: bool
使用str.repalce()对楼层进行加密(即将数字替换成’XX’)
df['floor'].str.replace(r'\d.','XX')[:5]
0 中层(共XX层)
1 中层(共XX层)
2 中层(共XX层)
3 中层(共XX层)
4 中层(共XX层)
Name: floor, dtype: object
# 使用str.findall()提取其中的数字
df['floor'].str.findall(r'\d.').str.get(0)[:5]
0 16
1 31
2 33
3 16
4 28
Name: floor, dtype: object
# 使用str.extract()指定捕获组以直接提取数字
df['floor'].str.extract(r'(\d.)',expand=False)[:5]
0 16
1 31
2 33
3 16
4 28
Name: floor, dtype: object
(6)对多个标签样本进行哑变量编码
使用str属性进行哑变量编码,并使用sep指定分隔符
s = pd.Series(["Animation,Children's,Comedy","Comedy,Romance","Animation","Comedy"])
s
0 Animation,Children's,Comedy
1 Comedy,Romance
2 Animation
3 Comedy
dtype: object
#对多个标签进行哑变量编码
s.str.get_dummies(sep=',')
| Animation | Children's | Comedy | Romance | |
|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
| 2 | 1 | 0 | 0 | 0 |
| 3 | 0 | 0 | 1 | 0 |
离散化、面元划分(等距pd.cut()、等频pd.pcut()))
有时在处理连续型数据时,为了方便分析,需要将其进行离散化或者是拆分成“面元(bin)”,即将数据放置于一个小区间中。
在Pandas中,cut()—>数据离散化
qcut()-->面元划分
一、cut():等距离散化,设置的bins的每个区间的间隔相等。
首先查看其最大值和最小值,便于了解将数据划分为多少个组别:在此将数据划分组别,如下:
df2 = pd.DataFrame({'class':['A','A','B','B','C','A'],
'name':['Bob','Bob','Mark','Miki','Sully','Rose'],
'city':['广州市','深圳市','上海市','重庆市','贵州市','北京市'],
'sex':['女','男','女','女','女','男'],
'score_math':[99,89,87,67,77,65],
'score_music':[78,81,91,72,67,99],})
df2['score_math'].max()
99
df2['score_math'].min()
65
bins = [60,70,80,90,100]
pd.cut(df2['score_math'],bins)[:5]
0 (90, 100]
1 (80, 90]
2 (80, 90]
3 (60, 70]
4 (70, 80]
Name: score_math, dtype: category
Categories (4, interval[int64]): [(60, 70] < (70, 80] < (80, 90] < (90, 100]]
通过labels参数可以将这些区间换成其他的字符串
pd.cut(df2['score_math'],bins=bins,labels=['A','B','C','D'])[:5]
0 D
1 C
2 C
3 A
4 B
Name: score_math, dtype: category
Categories (4, object): [A < B < C < D]
二、qcut():等频离散化,每个区间的样本数相同。
#分成8个等频区间
bs=pd.qcut(df2['score_math'],5)
bs
0 (89.0, 99.0]
1 (87.0, 89.0]
2 (77.0, 87.0]
3 (64.999, 67.0]
4 (67.0, 77.0]
5 (64.999, 67.0]
Name: score_math, dtype: category
Categories (5, interval[float64]): [(64.999, 67.0] < (67.0, 77.0] < (77.0, 87.0] < (87.0, 89.0] < (89.0, 99.0]]
#查看每个区间的样本数
bs.value_counts()
(64.999, 67.0] 2
(89.0, 99.0] 1
(87.0, 89.0] 1
(77.0, 87.0] 1
(67.0, 77.0] 1
Name: score_math, dtype: int64
从每个区间的样本数可以发现,每个区间的样本数挺不是完全相等的,所以:此处的等频真正的含义是每个区间的数量并不是理想中的等量,而是大致等量。
排序(df.sort_index()、df.sort_values()、随机重排、随机采样)
排序是一种索引机制的一种常见的操作方法,也是Pandas重要的内置运算,主要包括以下3种方法:
排序方法 说明
sort_values() 根据某一列的值进行排序
sort_index() 根据索引进行排序
随机重排 详见后面
一、sort_values()
注意:默认情况下sort_values()是升序排列,ascending = Fals表示降序;
sort_values()也可以对缺失值进行排序,默认情况下,缺失值是排在最后的,但是可以通过设置参数na_position=’first’将缺失值排在最前;
df2.sort_values('score_music',ascending=False)
| city | class | name | score_math | score_music | sex | |
|---|---|---|---|---|---|---|
| 5 | 北京市 | A | Rose | 65 | 99 | 男 |
| 2 | 上海市 | B | Mark | 87 | 91 | 女 |
| 1 | 深圳市 | A | Bob | 89 | 81 | 男 |
| 0 | 广州市 | A | Bob | 99 | 78 | 女 |
| 3 | 重庆市 | B | Miki | 67 | 72 | 女 |
| 4 | 贵州市 | C | Sully | 77 | 67 | 女 |
df2.sort_index(ascending=False)
| city | class | name | score_math | score_music | sex | |
|---|---|---|---|---|---|---|
| 5 | 北京市 | A | Rose | 65 | 99 | 男 |
| 4 | 贵州市 | C | Sully | 77 | 67 | 女 |
| 3 | 重庆市 | B | Miki | 67 | 72 | 女 |
| 2 | 上海市 | B | Mark | 87 | 91 | 女 |
| 1 | 深圳市 | A | Bob | 89 | 81 | 男 |
| 0 | 广州市 | A | Bob | 99 | 78 | 女 |
随机重排
sort_values()和sort_index()只能对DataFrame进行升序或降序排列,若希望随机打乱排列顺序(即随机重排),方法如下:
步骤1:使用numpy.random.permutation()产生一个重排后的整数数组【注:numpy.random.permutation可随机排列一个序列,返回一个随机排列后的序号】
步骤2:使用.iloc[]或take()得到重排后的Pandas对象。
#步骤一:取出随机序列
samlper=np.random.permutation(6)
samlper
array([3, 2, 1, 5, 0, 4])
df2
| city | class | name | score_math | score_music | sex | |
|---|---|---|---|---|---|---|
| 0 | 广州市 | A | Bob | 99 | 78 | 女 |
| 1 | 深圳市 | A | Bob | 89 | 81 | 男 |
| 2 | 上海市 | B | Mark | 87 | 91 | 女 |
| 3 | 重庆市 | B | Miki | 67 | 72 | 女 |
| 4 | 贵州市 | C | Sully | 77 | 67 | 女 |
| 5 | 北京市 | A | Rose | 65 | 99 | 男 |
#步骤二:以步骤一得到的随机序列为索引,取出这些数据
#take()函数
# df2.take(sampler)
#iloc方法
df2.iloc[samlper]
| city | class | name | score_math | score_music | sex | |
|---|---|---|---|---|---|---|
| 3 | 重庆市 | B | Miki | 67 | 72 | 女 |
| 2 | 上海市 | B | Mark | 87 | 91 | 女 |
| 1 | 深圳市 | A | Bob | 89 | 81 | 男 |
| 5 | 北京市 | A | Rose | 65 | 99 | 男 |
| 0 | 广州市 | A | Bob | 99 | 78 | 女 |
| 4 | 贵州市 | C | Sully | 77 | 67 | 女 |
随机采样
使用sample()进行随机采样,随机采样的量可通过参数n和frac来设置,n表示按照n指定的数量来进行抽样,frac表示按照指定的比例进行抽样。
注意:
(1)sample默认的是不放回采样(即每个样本只能出现一次),可以通过设置replace = True将其设置为有放回采样;
例如:>>>df.sample(n=5,replace = True)
(2)若希望重复某次采样的结果,可以设置random_state参数为同一个数来实现(random_state的大小没有任何意思,只是这是为同一个数来通知两次随机采样的结果相同):
例如:>>>df.sample(n=5,random_state=1)
(3)sample也可以实现列的随机采样,只需要设置axis=1即可:
例如:>>>df.sample(n=2,axis=1)[:5]
df2.sample(len(df2),replace=True)
| city | class | name | score_math | score_music | sex | |
|---|---|---|---|---|---|---|
| 5 | 北京市 | A | Rose | 65 | 99 | 男 |
| 0 | 广州市 | A | Bob | 99 | 78 | 女 |
| 1 | 深圳市 | A | Bob | 89 | 81 | 男 |
| 2 | 上海市 | B | Mark | 87 | 91 | 女 |
| 1 | 深圳市 | A | Bob | 89 | 81 | 男 |
| 4 | 贵州市 | C | Sully | 77 | 67 | 女 |
数据融合(pd.merge()、df.join()、df.combine_first()详解)
pd.merge()的常用参数
参数 说明
left 参与合并的左侧DataFrame
right 参与合并的右侧DataFrame
how 如何合并。值为{‘left’,’right’,’outer’,’inner’},默认为’inner’
left: 仅保留左侧DataFrame中存在的键
right:仅保留右侧DataFrame中存在的键
outer:保留左右DataFrame键的并集
inner:保留左右DataFrame键的交集
on 用于连接的列名,默认是两个DataFrame重叠的列
left_on 左侧DataFrame中用作连接键的列
right_on 右侧DataFrame中用作连接键的列
left_index {True,False},将左侧的行索引用作其连接键
right_index {True,False},将右侧的行做引用作其连接键
suffixes 字符串值元组,用于追加到重叠列名的后缀,默认为(’_x’,’_y’)
1)先创建两个DataFrame
left = pd.DataFrame({'姓名':['张某','李某','段某'],'年龄':[22,26,24]})
left
| 姓名 | 年龄 | |
|---|---|---|
| 0 | 张某 | 22 |
| 1 | 李某 | 26 |
| 2 | 段某 | 24 |
right = pd.DataFrame({'姓名':['张某','李某','钱某'],'籍贯':['北京','河北','江苏']})
right
| 姓名 | 籍贯 | |
|---|---|---|
| 0 | 张某 | 北京 |
| 1 | 李某 | 河北 |
| 2 | 钱某 | 江苏 |
(2)在默认情况下,将重叠列当做键,也可通过参数on指定;
pd.merge(left,right)
| 姓名 | 年龄 | 籍贯 | |
|---|---|---|---|
| 0 | 张某 | 22 | 北京 |
| 1 | 李某 | 26 | 河北 |
#通过参数on指定
pd.merge(left,right,on='姓名')
| 姓名 | 年龄 | 籍贯 | |
|---|---|---|---|
| 0 | 张某 | 22 | 北京 |
| 1 | 李某 | 26 | 河北 |
(3)融合指标变量indicator,设置indicator的值为True,则融合结果中将增加列名为”_merge”的一列,其值代表不同含义:
取值 说明
left_only 融合的键仅在左侧的DataFrame中存在
right_only 融合的键仅在右侧的DataFrame中存在
both 融合的键在左右两侧的DataFrame中均存在
pd.merge(left,right,on='姓名',how='outer',indicator=True)
| 姓名 | 年龄 | 籍贯 | _merge | |
|---|---|---|---|---|
| 0 | 张某 | 22.0 | 北京 | both |
| 1 | 李某 | 26.0 | 河北 | both |
| 2 | 段某 | 24.0 | NaN | left_only |
| 3 | 钱某 | NaN | 江苏 | right_only |
indicator也可以接受字符串,生成的指标列的列名将由”_merge“变为该字符串:
pd.merge(left,right,on='姓名',how='outer',indicator='indicator_column')
| 姓名 | 年龄 | 籍贯 | indicator_column | |
|---|---|---|---|---|
| 0 | 张某 | 22.0 | 北京 | both |
| 1 | 李某 | 26.0 | 河北 | both |
| 2 | 段某 | 24.0 | NaN | left_only |
| 3 | 钱某 | NaN | 江苏 | right_only |
(4)索引与列进行融合
注:left的索引和right中的某一列均为“姓名”,现在需要根据姓名进行融合
left = pd.DataFrame({'年龄':[22,26,24]},index=['张某','李某','段某'])
left
| 年龄 | |
|---|---|
| 张某 | 22 |
| 李某 | 26 |
| 段某 | 24 |
left.index.name='姓名'
left
| 年龄 | |
|---|---|
| 姓名 | |
| 张某 | 22 |
| 李某 | 26 |
| 段某 | 24 |
#其中,left的索引和right中的某一列均为“姓名”,现在需要根据姓名进行融合
pd.merge(left,right,how='outer',left_index=True,right_on='姓名')
| 年龄 | 姓名 | 籍贯 | |
|---|---|---|---|
| 0 | 22.0 | 张某 | 北京 |
| 1 | 26.0 | 李某 | 河北 |
| 2 | 24.0 | 段某 | NaN |
| 2 | NaN | 钱某 | 江苏 |
(5)索引与索引的融合
left和right的索引均为‘姓名’,现进行融合
left = pd.DataFrame({'年龄':[22,26,24]},index=['张某','李某','段某'])
right.index.name='姓名'
right = pd.DataFrame({'籍贯':['北京','河北','江苏']},index=['张某','李某','钱某'])
left.index.name='姓名'
right
| 籍贯 | |
|---|---|
| 张某 | 北京 |
| 李某 | 河北 |
| 钱某 | 江苏 |
#left和right的索引均为‘姓名’,现进行融合
pd.merge(left,right,how='outer',left_index=True,right_index=True)
| 年龄 | 籍贯 | |
|---|---|---|
| 张某 | 22.0 | 北京 |
| 李某 | 26.0 | 河北 |
| 段某 | 24.0 | NaN |
| 钱某 | NaN | 江苏 |
二、join()
join()函数相对于pd.merge()而言是一种更为简便的实现方式
(1)对于索引与列的融合,需要设置on参数,来指明左键
注意:此时on的值应该是具体的列,而不是索引,索引此时的实体(即join左边的对象应该是包含“姓名”列的DataFrame)
#注意:此时on的值应该是具体的列,而不是索引,索引此时的实体(即join左边的对象应该是包含“姓名”列的DataFrame)
left
| 年龄 | |
|---|---|
| 姓名 | |
| 张某 | 22 |
| 李某 | 26 |
| 段某 | 24 |
right
| 姓名 | 籍贯 | |
|---|---|---|
| 0 | 张某 | 北京 |
| 1 | 李某 | 河北 |
| 2 | 钱某 | 江苏 |
right.join(left,on='姓名')
| 姓名 | 籍贯 | 年龄 | |
|---|---|---|---|
| 0 | 张某 | 北京 | 22.0 |
| 1 | 李某 | 河北 | 26.0 |
| 2 | 钱某 | 江苏 | NaN |
(2)索引与索引的融合
相当于>>>pd.merge(left,right,how=’outer’,left_index=True,right_index=True)
left.join(right,how='outer')
| 年龄 | 籍贯 | |
|---|---|---|
| 张某 | 22.0 | 北京 |
| 李某 | 26.0 | 河北 |
| 段某 | 24.0 | NaN |
| 钱某 | NaN | 江苏 |
注意:merge和joiny都有参数sort,当sort=True时表示连接后的结果会按照连接变量进行升序排列。
例:>>>pd.merge(test_user,test_loan,how=’outer’,left_on=’user_id’,right_on=’user’,sort=True)
三、combine_first()
由于数据融合是有一种常见的现象,即:需要根据一个DataFrame对象中的值为另一个DataFrame中的值做缺失值处理;
于是combine_first()应运而生,该方法实现了用参数对象中的数据为调用者对象的缺失数据“打补丁”,且会自动对其索引。
left = pd.DataFrame({'姓名':['张某','李某','段某'],'年龄':[22,26,24]})
right = pd.DataFrame({'姓名':['张某','李某','段某'],'年龄':[22,np.nan,np.nan],'籍贯':['北京','河北','江苏']})
#根据left中的值去填补right中的值
right.combine_first(left)
| 姓名 | 年龄 | 籍贯 | |
|---|---|---|---|
| 0 | 张某 | 22.0 | 北京 |
| 1 | 李某 | 26.0 | 河北 |
| 2 | 段某 | 24.0 | 江苏 |
数据合并与轴向连接(pd.concat()的详解)
数据合并:由于数据可能是不同的格式,且来自不同的数据源,为了方便之后的处理与加工,需要将不同的数据转换成一个DataFrame。
Numpy中的concatenate()、vstack()、hstack()可对数组进行拼接,可参考学习。
Pandas提供了pd.concat()、pd.merge()、join()、combine_first()等函数对Pandas数据对象进行合并。
pd.concat()常用的参数
参数 说明
objs 需连接的对象的列表
axis 轴向连接所沿的轴,默认为0
ignore_index 默认False,当为True时表示不适用连接轴上的索引值,生成的轴标记为
0…n-1
keys 序列,默认为None。构建层次化索引,且该索引位于最外层
join 值为’inner’或’outer’(默认’outer’)。指定处理其他轴上的索引(并集或交集)
join_axes 指定其他轴上的索引,不执行并集或交集运算
(1)默认连接两个DataFrame对象(默认axis = 0,即上下连接)
import pandas as pd
df3 = pd.DataFrame({'年龄':[22,26],'籍贯':['北京','河北']},index=['张某','李某'])
df4 = pd.DataFrame({'身高':[175,180],'体重':[70,85]},index=['张某','李某'])
pd.concat([df3,df4])
| 体重 | 年龄 | 籍贯 | 身高 | |
|---|---|---|---|---|
| 张某 | NaN | 22.0 | 北京 | NaN |
| 李某 | NaN | 26.0 | 河北 | NaN |
| 张某 | 70.0 | NaN | NaN | 175.0 |
| 李某 | 85.0 | NaN | NaN | 180.0 |
(2)左右连接两个DataFrame对象
pd.concat([df3,df4],axis=1)
| 年龄 | 籍贯 | 体重 | 身高 | |
|---|---|---|---|---|
| 张某 | 22 | 北京 | 70 | 175 |
| 李某 | 26 | 河北 | 85 | 180 |
(3)验证ignore_index参数,即将连接后的列名转化为0…n-1
pd.concat([df3,df4],axis=1,ignore_index=True)
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 张某 | 22 | 北京 | 70 | 175 |
| 李某 | 26 | 河北 | 85 | 180 |
(4)验证keys参数,即构建层次化索引
pd.concat([df3,df4],axis=1,keys=['df3','df4'])
| df3 | df4 | |||
|---|---|---|---|---|
| 年龄 | 籍贯 | 体重 | 身高 | |
| 张某 | 22 | 北京 | 70 | 175 |
| 李某 | 26 | 河北 | 85 | 180 |
(5)验证join参数,默认 join = ‘outer’ ,取并集,不会造成信息的缺失
df5 = pd.DataFrame({'身高':[175,183],'体重':[70,87]},index=['张某','钱某'])
#取并集
pd.concat([df5,df3],axis=1)
| 体重 | 身高 | 年龄 | 籍贯 | |
|---|---|---|---|---|
| 张某 | 70.0 | 175.0 | 22.0 | 北京 |
| 李某 | NaN | NaN | 26.0 | 河北 |
| 钱某 | 87.0 | 183.0 | NaN | NaN |
#交集
pd.concat([df5,df3],axis=1,join='inner')
| 体重 | 身高 | 年龄 | 籍贯 | |
|---|---|---|---|---|
| 张某 | 70 | 175 | 22 | 北京 |
df3
| 年龄 | 籍贯 | |
|---|---|---|
| 张某 | 22 | 北京 |
| 李某 | 26 | 河北 |
(6)验证join_axes参数,若只想重用原始DataFrame中的索引,则项 join_axes 传入一个索引对象列表
pd.concat([df5,df3],axis=1,join_axes=[df3.index])
| 体重 | 身高 | 年龄 | 籍贯 | |
|---|---|---|---|---|
| 张某 | 70.0 | 175.0 | 22 | 北京 |
| 李某 | NaN | NaN | 26 | 河北 |
数据分组与聚合(df.Groupby())
GroupBy技术是对于数据进行分组计算并将各组计算结果合并的一项技术,包括以下3个过程:
拆分(Spliting):即将数据进行分组
应用(Applying):对每组应用函数进行计算
合并(Combining):将计算结果进行数据聚合
使用GroupBy()可以沿着任意轴进行分组,并且将分组依据的键作为每组的组名,有一下3种用法:
df.groupby(key)
df.groupby(key,axis=1)
df.groupby([key1,key2])
注:key需要用””引起来
其中的参数axis,可设置是横向分组还是纵向分组,默认是横向分组(axis=0),也是比较常用的。
import pandas as pd
import numpy as np
df = pd.DataFrame({'class':['A','A','B','B','C','A'],
'name':['Bob','Bob','Mark','Miki','Sully','Rose'],
'city':['广州市','深圳市','上海市','重庆市','贵州市','北京市'],
'sex':['女','男','女','女','女','男'],
'score_math':[99,99,87,77,77,65],
'score_music':[78,81,91,72,67,99],})
#使用groupby()按照class进行分组,返回的结果是一个GroupBY对象,即拆分过程
# 分组时所依据的键的唯一值作为索引,且当传入多个值时将产生层次化索引
df.groupby('class').sum()
| score_math | score_music | |
|---|---|---|
| class | ||
| A | 263 | 258 |
| B | 164 | 163 |
| C | 77 | 67 |
df.groupby(['class','sex']).mean()
| score_math | score_music | ||
|---|---|---|---|
| class | sex | ||
| A | 女 | 99.0 | 78.0 |
| 男 | 82.0 | 90.0 | |
| B | 女 | 82.0 | 81.5 |
| C | 女 | 77.0 | 67.0 |
在分组时除了传入列表,也可传入一个对于对象行或列长度一致的数组。(并不常用)
例:求按性别分组的各课程平均分,传入性别使用中文表示的一个数组
arr = np.array(['男','女','女','男','女','男'])
df.groupby(arr).mean()
| score_math | score_music | |
|---|---|---|
| 女 | 87.666667 | 79.666667 |
| 男 | 80.333333 | 83.000000 |
.count()函数可统计各组样本数量,.idxmax()函数可返回最大值的索引
#按照class和sex分组后各组样本的数量
df.groupby(['class','sex']).count()
| city | name | score_math | score_music | ||
|---|---|---|---|---|---|
| class | sex | ||||
| A | 女 | 1 | 1 | 1 | 1 |
| 男 | 2 | 2 | 2 | 2 | |
| B | 女 | 2 | 2 | 2 | 2 |
| C | 女 | 1 | 1 | 1 | 1 |
##按照class和sex分组后最大值的索引
df.groupby(['class','sex']).idxmax()
| score_math | score_music | ||
|---|---|---|---|
| class | sex | ||
| A | 女 | 0 | 0 |
| 男 | 1 | 5 | |
| B | 女 | 2 | 2 |
| C | 女 | 4 | 4 |
#按照class和sex分组后样本数量最多的索引
df.groupby(['class','sex']).count().idxmax()
city (A, 男)
name (A, 男)
score_math (A, 男)
score_music (A, 男)
dtype: object
分组的基本方法(分组大小与排序、迭代、指定组或列)
数据分组的基本方法有3种:
- 分组大小和分组排序
- 对分组进行迭代
- 选择指定组或指定的列
一、分组大小和分组排序
可通过GroupBy对象的size()方法,知道每个分组的样本数;
df.groupby(['class']).size()
class
A 3
B 2
C 1
dtype: int64
df.groupby(['class','sex']).size()
class sex
A 女 1
男 2
B 女 2
C 女 1
dtype: int64
在默认情况下,分组聚合后的索引会进行排序,可能会降低运行速度,所以,在数据量很大的时候可以设置sort = False,指定不进行排序以提高分组速度;
df.groupby('class',sort=False).mean()
| score_math | score_music | |
|---|---|---|
| class | ||
| A | 87.666667 | 86.0 |
| B | 82.000000 | 81.5 |
| C | 77.000000 | 67.0 |
二、对分组进行迭代
GroupBy对象是一个可迭代对象,所以可以通过迭代获取分组名和数据;
例如:获取班级的分组名和数据(若按多个键进行分组,则分组名变成元组)
grouped = df.groupby('class')
for name,group in grouped:
print(name)
print(group)
print('-'*40)
A
city class name score_math score_music sex
0 广州市 A Bob 99 78 女
1 深圳市 A Bob 99 81 男
5 北京市 A Rose 65 99 男
----------------------------------------
B
city class name score_math score_music sex
2 上海市 B Mark 87 91 女
3 重庆市 B Miki 77 72 女
----------------------------------------
C
city class name score_math score_music sex
4 贵州市 C Sully 77 67 女
----------------------------------------
三、选择指定组或指定的列
(1)将分组名及其数据封装成一个字典,便于后序选择指定组的数据;
值得注意的是:不可直接将GroupBy对象打包成字典,必须先将其转化成包含多个元组的列表,才能使用dict()将其转换成字典。
grouped = df.groupby('class')
pieces = dict(list(grouped))
len(pieces)
3
pieces.keys()
dict_keys(['A', 'B', 'C'])
pieces['A']
| city | class | name | score_math | score_music | sex | |
|---|---|---|---|---|---|---|
| 0 | 广州市 | A | Bob | 99 | 78 | 女 |
| 1 | 深圳市 | A | Bob | 99 | 81 | 男 |
| 5 | 北京市 | A | Rose | 65 | 99 | 男 |
(2)GroupBy对象的get_group()也可以达到同样的效果而且更直观
grouped.get_group('A')
| city | class | name | score_math | score_music | sex | |
|---|---|---|---|---|---|---|
| 0 | 广州市 | A | Bob | 99 | 78 | 女 |
| 1 | 深圳市 | A | Bob | 99 | 81 | 男 |
| 5 | 北京市 | A | Rose | 65 | 99 | 男 |
(3)若只需要对指定的列进行GroupBy操作,只需在groupby()后加上指定的列即可
df.groupby('class')['score_math','score_music'].mean()
| score_math | score_music | |
|---|---|---|
| class | ||
| A | 87.666667 | 86.0 |
| B | 82.000000 | 81.5 |
| C | 77.000000 | 67.0 |
数组分组的高级方法(使用字典、函数、层次化索引级别)
数据分组的高级方法有3种:
- 通过字典进行分组
- 通过函数进行分组
- 根据层次化索引级别进行分组
一、根据字典进行分组
若希望按照特征类别进行分组,可创建一个映射字典
df1=pd.DataFrame({'A_male':[87,68,89,66],'B_female':[56,78,85,89],'C_female':[98,87,57,89],'D_male':[87,95,85,75]})
df1
| A_male | B_female | C_female | D_male | |
|---|---|---|---|---|
| 0 | 87 | 56 | 98 | 87 |
| 1 | 68 | 78 | 87 | 95 |
| 2 | 89 | 85 | 57 | 85 |
| 3 | 66 | 89 | 89 | 75 |
#创建一个映射字典
mapper = {'A_male':'Male','B_female':'Female','C_female':'Female','D_male':'Male'}
#通过传入硬着字典,指定分组依据位于列上,对不同类别的特征进行分组
grouped=df1.groupby(mapper,axis=1)
#获取分组信息
grouped.get_group('Male')
| A_male | D_male | |
|---|---|---|
| 0 | 87 | 87 |
| 1 | 68 | 95 |
| 2 | 89 | 85 |
| 3 | 66 | 75 |
# 对各组数据按照横向轴进行计算
grouped.mean()
| Female | Male | |
|---|---|---|
| 0 | 77.0 | 87.0 |
| 1 | 82.5 | 81.5 |
| 2 | 71.0 | 87.0 |
| 3 | 89.0 | 70.5 |
二、根据函数进行分组
假设对行索引进行分组,可以自定义一函数:当索引值为3时,返回 False ;当索引部位3时返回True;
注意:使用函数对数据进行分组时,函数输入的是数据的索引列
grouped
<pandas.core.groupby.DataFrameGroupBy object at 0x000001DCD12B7470>
map_fuc=lambda x:bool(3-x)
grouped=df1.groupby(map_fuc)
for name,group in grouped:
print(name)
print(group)
print('-'*40)
False
A_male B_female C_female D_male
3 66 89 89 75
----------------------------------------
True
A_male B_female C_female D_male
0 87 56 98 87
1 68 78 87 95
2 89 85 57 85
----------------------------------------
三、根据层次化索引进行分组
先创建一个存在层次化索引的DataFrame对象,如下:
hier_df = pd.DataFrame([[78,85],[89,96],[88,94],[90,95]],columns=['math','music'],index=[['A','B','B','C'],['male','female','male','female']])
hier_df
| math | music | ||
|---|---|---|---|
| A | male | 78 | 85 |
| B | female | 89 | 96 |
| male | 88 | 94 | |
| C | female | 90 | 95 |
hier_df.index.names=['class','sex']
hier_df
| math | music | ||
|---|---|---|---|
| class | sex | ||
| A | male | 78 | 85 |
| B | female | 89 | 96 |
| male | 88 | 94 | |
| C | female | 90 | 95 |
当DataFrame对象存在层次化索引之时可以通过参数level指定不同索引级别进行分组与聚合;也可以直接指定列无需指定level
上述例子中的class索引的level=0,sex索引的level=1
hier_df.groupby(level=0).mean()
| math | music | |
|---|---|---|
| class | ||
| A | 78.0 | 85.0 |
| B | 88.5 | 95.0 |
| C | 90.0 | 95.0 |
hier_df.groupby('sex').mean()
#与直接指定列效果一致
hier_df.groupby(level=1).mean()
| math | music | |
|---|---|---|
| sex | ||
| female | 89.5 | 95.5 |
| male | 83.0 | 89.5 |
在分组结果中,若不想分组的键当做索引,设置as_index = Fasle即可,默认的as_index = True
hier_df.groupby(level=1,as_index=False).mean()
| math | music | |
|---|---|---|
| 0 | 89.5 | 95.5 |
| 1 | 83.0 | 89.5 |
数据分组的函数应用(df.apply()、df.agg()和df.transform()、df.applymap())
将自己定义的或其他库的函数应用于Pandas对象,有以下3种方法:
apply():逐行或逐列应用该函数
agg()和transform():聚合和转换
applymap():逐元素应用函数
一 、apply()
其中:设置axis = 1参数,可以逐行进行操作;默认axis=0,即逐列进行操作;
对于常见的描述性统计方法,可以直接使用一个字符串进行代替,例df.apply(‘mean’)等价于df.apply(np.mean);
import pandas as pd
import numpy as np
df = pd.DataFrame({'class':['A','A','B','B','C','A'],
'name':['Bob','Bob','Mark','Miki','Sully','Rose'],
'city':['广州市','深圳市','上海市','重庆市','贵州市','北京市'],
'sex':['女','男','女','女','女','男'],
'score_math':[99,99,87,77,77,65],
'score_music':[78,81,91,72,67,99],})
df = df[['score_math','score_music']]
df
| score_math | score_music | |
|---|---|---|
| 0 | 99 | 78 |
| 1 | 99 | 81 |
| 2 | 87 | 91 |
| 3 | 77 | 72 |
| 4 | 77 | 67 |
| 5 | 65 | 99 |
#对音乐课和数学课逐列求成绩平均分
df.apply(np.mean)
score_math 84.000000
score_music 81.333333
dtype: float64
type(df.apply(np.mean))
pandas.core.series.Series
df['score_math'].apply('mean')
84.0
type(df['score_math'].apply(np.mean))
pandas.core.series.Series
#逐行求每个学生的平均分
df.apply(np.mean,axis=1)
0 88.5
1 90.0
2 89.0
3 74.5
4 72.0
5 82.0
dtype: float64
type(df.apply(np.mean,axis=1))
pandas.core.series.Series
apply()的返回结果与所用的函数是相关的:
返回结果是Series对象:如上述例子应用的均值函数,就是每一行或每一列返回一个值;
返回大小相同的DataFrame:如下面自定的lambda函数。
#其中的x可以看作是每一类的Series对象
df.apply(lambda x: x - 5)
| score_math | score_music | |
|---|---|---|
| 0 | 94 | 73 |
| 1 | 94 | 76 |
| 2 | 82 | 86 |
| 3 | 72 | 67 |
| 4 | 72 | 62 |
| 5 | 60 | 94 |
type(df.apply(lambda x: x - 5))
pandas.core.frame.DataFrame
二、数据聚合agg()
数据聚合agg()指任何能够从数组产生标量值的过程;
相当于apply()的特例,可以对pandas对象进行逐行或逐列的处理;
能使用agg()的地方,基本上都可以使用apply()代替。
例:
1)对两门课逐列求平均分
df.agg('mean')
df.apply('mean')
score_math 84.000000
score_music 81.333333
dtype: float64
2)应用多个函数,可将函数放于一个列表中;
例:对两门课分别求最高分与最低分
df.agg(['max','min'])
| score_math | score_music | |
|---|---|---|
| max | 99 | 99 |
| min | 65 | 67 |
df.apply([np.max,np.min])
# df.apply([np.max,'min'])
| score_math | score_music | |
|---|---|---|
| amax | 99 | 99 |
| amin | 65 | 67 |
3)使用字典可以对特定列应用特定及多个函数;
例:对数学成绩求均值和最小值,对音乐课求最大值
df.agg({'score_math':['mean','min'],'score_music':'max'})
| score_math | score_music | |
|---|---|---|
| max | NaN | 99.0 |
| mean | 84.0 | NaN |
| min | 65.0 | NaN |
三、数据转换transform()
特点:使用一个函数后,返回相同大小的Pandas对象
与数据聚合agg()的区别:
数据聚合agg()返回的是对组内全量数据的缩减过程;
数据转换transform()返回的是一个新的全量数据。
注意:df.transform(np.mean)将报错,转换是无法产生聚合结果的
#将成绩减去各课程的平均分,使用apply、agg、transfrom都可以实现
df.transform(lambda x:x-x.mean())
df.apply(lambda x:x-x.mean())
df.agg(lambda x:x-x.mean())
| score_math | score_music | |
|---|---|---|
| 0 | 15.0 | -3.333333 |
| 1 | 15.0 | -0.333333 |
| 2 | 3.0 | 9.666667 |
| 3 | -7.0 | -9.333333 |
| 4 | -7.0 | -14.333333 |
| 5 | -19.0 | 17.666667 |
当应用多个函数时,将返回于原始DataFrame大小不同的DataFrame,返回结果中:
在列索引上第一级别是原始列名
在第二级别上是转换的函数名
df.transform([lambda x:x-x.mean(),lambda x:x/10])
| score_math | score_music | |||
|---|---|---|---|---|
| <lambda> | <lambda> | <lambda> | <lambda> | |
| 0 | 15.0 | 9.9 | -3.333333 | 7.8 |
| 1 | 15.0 | 9.9 | -0.333333 | 8.1 |
| 2 | 3.0 | 8.7 | 9.666667 | 9.1 |
| 3 | -7.0 | 7.7 | -9.333333 | 7.2 |
| 4 | -7.0 | 7.7 | -14.333333 | 6.7 |
| 5 | -19.0 | 6.5 | 17.666667 | 9.9 |
四、applymap()
applymap()对pandas对象逐元素应用某个函数,成为元素级函数应用;
与map()的区别:
- applymap()是DataFrame的实例方法
- map()是Series的实例方法
例:对成绩保留小数后两位
df.applymap(lambda x:'%.2f'%x)
| score_math | score_music | |
|---|---|---|
| 0 | 99.00 | 78.00 |
| 1 | 99.00 | 81.00 |
| 2 | 87.00 | 91.00 |
| 3 | 77.00 | 72.00 |
| 4 | 77.00 | 67.00 |
| 5 | 65.00 | 99.00 |
df['score_math'].map(lambda x:'%.2f'%x)
0 99.00
1 99.00
2 87.00
3 77.00
4 77.00
5 65.00
Name: score_math, dtype: object
df = pd.DataFrame({'class':['A','A','B','B','C','A'],
'name':['Bob','Bob','Mark','Miki','Sully','Rose'],
'city':['广州市','深圳市','上海市','重庆市','贵州市','北京市'],
'sex':['女','男','女','女','女','男'],
'score_math':[99,99,87,77,77,65],
'score_music':[78,81,91,72,67,99],})
grouped = df.groupby('class')
grouped.sum()
# 相当于
grouped.agg('sum')
| score_math | score_music | |
|---|---|---|
| class | ||
| A | 263 | 258 |
| B | 164 | 163 |
| C | 77 | 67 |
可以同时使用多个聚合函数(使用列表的格式),其结果将包含一个层次化索引,新加的索引名称是函数的名称。
数据聚合也可使用自定义聚合函数:自定义的函数必须具有聚合的作用,若传入一个一个数组(1维),必须只能返回标量值(0维)
需要注意的是:在构造中间分组数据块时可能存在函数调用、数据重排等较大的开销。
grouped.agg([np.sum,lambda x:x.max()-x.min()])
| score_math | score_music | |||
|---|---|---|---|---|
| sum | <lambda> | sum | <lambda> | |
| class | ||||
| A | 263 | 34 | 258 | 21 |
| B | 164 | 10 | 163 | 19 |
| C | 77 | 0 | 67 | 0 |
在列表中传入一个二元元组(函数名,函数),可以更改列名;
grouped.agg([('sum',np.sum),('range',lambda x:x.max()-x.min())])
| score_math | score_music | |||
|---|---|---|---|---|
| sum | range | sum | range | |
| class | ||||
| A | 263 | 34 | 258 | 21 |
| B | 164 | 10 | 163 | 19 |
| C | 77 | 0 | 67 | 0 |
对于不同的列执行不同的聚合运算,可以向agg()函数传入一个字典,将多个函数运用到至少一列时,聚合结果才会拥有层次化索引;
所以,在单独的运用一个函数时,若需要显示层次化索引,就可以使用列表的形式“假装”要对某一列运用多个聚合运算。
map_func = {'score_math':[np.mean,np.max],'score_music':[np.mean,np.min]}
grouped.agg(map_func)
| score_math | score_music | |||
|---|---|---|---|---|
| mean | amax | mean | amin | |
| class | ||||
| A | 87.666667 | 99 | 86.0 | 78 |
| B | 82.000000 | 87 | 81.5 | 72 |
| C | 77.000000 | 77 | 67.0 | 67 |
#假装要对某一列进行多个聚合运算,以达到层次化索引的结果
map_func = {'score_math':[np.max],'score_music':['mean']}
grouped.agg(map_func)
| score_math | score_music | |
|---|---|---|
| amax | mean | |
| class | ||
| A | 99 | 86.0 |
| B | 87 | 81.5 |
| C | 77 | 67.0 |
从上述例子可以看出,applymap()操作实际上是对每列的Series对象进行了map()操作
通过以上分析我们可以看到,apply、agg、transform三种方法都可以对分组数据进行函数操作,但也各有特色,总结如下:
apply中自定义函数对每个分组数据单独进行处理,再将结果合并;整个DataFrame的函数输出可以是标量、Series或DataFrame;每个apply语句只能传入一个函数;
agg可以通过字典方式指定特征进行不同的函数操作,每一特征的函数输出必须为标量;
transform不可以通过字典方式指定特征进行不同的函数操作,但函数运算单位也是DataFrame的每一特征,每一特征的函数输出可以是标量或者Series,但标量会被广播。
缺失值处理与丢弃数据(填充fillna()、删除drop()、drop_duplicates()、dropna())
一、了解缺失值
通常使用 NA(‘not available’)来代指缺失值
在Pandas的数据结构中,缺失值使用 NaN(‘Not a Number’)进行标识
除了汇总统计方法,还可以使用isnull()来对数据中缺失的样本占比、特征大致的缺失情况进行了解。
二、缺失值填充—fillna()
使用fillna()方法进行缺失值填补
填充方式分为以下几种:
(1)使用同一个值填补所有的缺失值
(2)向前填充、向后填充—>通过设置参数method参数来实现
method参数 说明
ffill或pad 向前填充值
bfill或backfill 向后填充值
import pandas as pd
import numpy as np
df = pd.DataFrame({'one':[23,23,23,23,23,23],
'two':[23,97,np.NaN,75,np.NaN,87],
'three':[23,76,78,np.NaN,67,np.NaN],
})
# df.fillna(method='pad')
df.fillna(method='bfill')
| one | three | two | |
|---|---|---|---|
| 0 | 23 | 23.0 | 23.0 |
| 1 | 23 | 76.0 | 97.0 |
| 2 | 23 | 78.0 | 75.0 |
| 3 | 23 | 67.0 | 75.0 |
| 4 | 23 | 67.0 | 87.0 |
| 5 | 23 | NaN | 87.0 |
(3)对不同列的缺失值使用不同的值进行填补
可以使用字典的方式,如下:
df.fillna({'two':1,'three':3})
| one | three | two | |
|---|---|---|---|
| 0 | 23 | 23.0 | 23.0 |
| 1 | 23 | 76.0 | 97.0 |
| 2 | 23 | 78.0 | 1.0 |
| 3 | 23 | 3.0 | 75.0 |
| 4 | 23 | 67.0 | 1.0 |
| 5 | 23 | 3.0 | 87.0 |
(4)使用一个Pandas的自动对齐功能进行填补
这也是最常使用的一种方式
df.fillna({'three':df['three'].mean()})
| one | three | two | |
|---|---|---|---|
| 0 | 23 | 23.0 | 23.0 |
| 1 | 23 | 76.0 | 97.0 |
| 2 | 23 | 78.0 | NaN |
| 3 | 23 | 61.0 | 75.0 |
| 4 | 23 | 67.0 | NaN |
| 5 | 23 | 61.0 | 87.0 |
三、丢弃数据
在一些实际的应用场景中,需要根据某些过滤条件丢弃部分无用数据,在多数情况下数据过滤可以同时达到获取和丢弃数据的目的。
除了使用布尔表达式之外,Pandas对象还有以下三种方法来丢弃无用数据:
drop():根据标签丢弃数据
drop_duplicates():丢弃重复数据
dropna():丢失缺失数据
(1)根据标签丢弃数据—-drop()
drop()可以根据标签丢弃多行或多了数据,基本参数如下:
labels:单个或者多个标签,传入类列表值(列表、array等)
axis:丢弃行(0,默认)或者列(1)
inplace:是否用结果替换原pandas对象(默认False)
df = pd.DataFrame({'one':[23,23,23,23,23,23],
'two':[23,97,np.NaN,75,np.NaN,87],
'three':[23,76,78,np.NaN,67,np.NaN],
})
df.index=['a','b','c','d','e','f']
df
| one | three | two | |
|---|---|---|---|
| a | 23 | 23.0 | 23.0 |
| b | 23 | 76.0 | 97.0 |
| c | 23 | 78.0 | NaN |
| d | 23 | NaN | 75.0 |
| e | 23 | 67.0 | NaN |
| f | 23 | NaN | 87.0 |
df.drop(labels=['three'],axis=1)
| one | two | |
|---|---|---|
| a | 23 | 23.0 |
| b | 23 | 97.0 |
| c | 23 | NaN |
| d | 23 | 75.0 |
| e | 23 | NaN |
| f | 23 | 87.0 |
(2)丢弃重复数据—-drop_duplicates()
1)由于不同的原因,数据中可能会包含重复出现的行(记录),重复的记录会造成信息的冗余,但是在实际中丢弃重复数据需要谨慎,盲目去重可以会造成数据集丢失部分数据。
duplicated()方法可以返回一个布尔型的Series,表示各行是否重复,仅仅将重复的最后一行标记为True;
注:duplicated()方法有参数keep,keep的值有一下三种情况:
keep = ‘first’—->返回结果中的第一个重复的数据
keep = ‘last’—–>返回结果中的最后一个重复的数据
keep = False——>所有的重复数据为True
new =pd.DataFrame({'one':pd.Series([23,23],index=['g','h']),'two':pd.Series([23,23],index=['g','h']),'three':pd.Series([23,76],index=['g','h'])})
new
| one | three | two | |
|---|---|---|---|
| g | 23 | 23 | 23 |
| h | 23 | 76 | 23 |
new_df = pd.concat([df,new])
new_df
| one | three | two | |
|---|---|---|---|
| a | 23 | 23.0 | 23.0 |
| b | 23 | 76.0 | 97.0 |
| c | 23 | 78.0 | NaN |
| d | 23 | NaN | 75.0 |
| e | 23 | 67.0 | NaN |
| f | 23 | NaN | 87.0 |
| g | 23 | 23.0 | 23.0 |
| h | 23 | 76.0 | 23.0 |
new_df.duplicated()#查看各行是否重复
a False
b False
c False
d False
e False
f False
g True
h False
dtype: bool
#通过布尔过滤可以丢弃重复数据
new_df[new_df.duplicated()==False]
| one | three | two | |
|---|---|---|---|
| a | 23 | 23.0 | 23.0 |
| b | 23 | 76.0 | 97.0 |
| c | 23 | 78.0 | NaN |
| d | 23 | NaN | 75.0 |
| e | 23 | 67.0 | NaN |
| f | 23 | NaN | 87.0 |
| h | 23 | 76.0 | 23.0 |
new_df.duplicated(keep=False)
a True
b False
c False
d False
e False
f False
g True
h False
dtype: bool
2)Pandas提供的drop_duplicates()可以更加简便的完成去重操作,默认情况下会判断各行的全部列,若只希望根据某一列判断重复项,则在括号后加入列即可。
new_df
| one | three | two | |
|---|---|---|---|
| a | 23 | 23.0 | 23.0 |
| b | 23 | 76.0 | 97.0 |
| c | 23 | 78.0 | NaN |
| d | 23 | NaN | 75.0 |
| e | 23 | 67.0 | NaN |
| f | 23 | NaN | 87.0 |
| g | 23 | 23.0 | 23.0 |
| h | 23 | 76.0 | 23.0 |
# new_df.drop_duplicates()
new_df.drop_duplicates(['one','three'])
| one | three | two | |
|---|---|---|---|
| a | 23 | 23.0 | 23.0 |
| b | 23 | 76.0 | 97.0 |
| c | 23 | 78.0 | NaN |
| d | 23 | NaN | 75.0 |
| e | 23 | 67.0 | NaN |
(3)丢弃缺失值数据—-dropna()
在含有缺失值样本比例较小的情况下,可以考虑丢弃缺失值所在的行,或者说一个特征大部分都是缺失值是,也可以考虑丢弃该特征。
dropna()方法用于丢弃缺失值相关数据,其常用的参数如下:
axis:丢弃缺失值所在的行(0,默认)或所在列(1);
how:’any’表示只要存在缺失值就丢弃(默认),’all’表示所有的值均为缺失值才丢弃;
subset:考虑部分行和列
inplace:是否替换原来的Pandas对象
df
| one | three | two | |
|---|---|---|---|
| a | 23 | 23.0 | 23.0 |
| b | 23 | 76.0 | 97.0 |
| c | 23 | 78.0 | NaN |
| d | 23 | NaN | 75.0 |
| e | 23 | 67.0 | NaN |
| f | 23 | NaN | 87.0 |
df.dropna(how='any')#若要删除存在缺失值所在的行
| one | three | two | |
|---|---|---|---|
| a | 23 | 23.0 | 23.0 |
| b | 23 | 76.0 | 97.0 |
# df.drop(labels=['three'],axis=1)
df.drop(['a','b'])
| one | three | two | |
|---|---|---|---|
| c | 23 | 78.0 | NaN |
| d | 23 | NaN | 75.0 |
| e | 23 | 67.0 | NaN |
| f | 23 | NaN | 87.0 |
import pandas as pd
import numpy as np
df = pd.DataFrame({'class':['A','A','B','B','C','A'],
'name':['Bob','Bob','Mark','Miki','Sully','Rose'],
'city':['广州市','深圳市','上海市','重庆市','贵州市','北京市'],
'sex':['女','男','女','女','女','男'],
'score_math':[99,99,87,77,77,65],
'haha':['女','男','女','女','女','男'],
'score_music':[78,81,91,72,67,99],
})
df
| class | name | city | sex | score_math | haha | score_music | |
|---|---|---|---|---|---|---|---|
| 0 | A | Bob | 广州市 | 女 | 99 | 女 | 78 |
| 1 | A | Bob | 深圳市 | 男 | 99 | 男 | 81 |
| 2 | B | Mark | 上海市 | 女 | 87 | 女 | 91 |
| 3 | B | Miki | 重庆市 | 女 | 77 | 女 | 72 |
| 4 | C | Sully | 贵州市 | 女 | 77 | 女 | 67 |
| 5 | A | Rose | 北京市 | 男 | 65 | 男 | 99 |
# 特征重复(一列数据和另一列数据的值相似度高,主要用于类别特征重复)
def FeatureEquals(data):
dfEquals=pd.DataFrame([],columns=data.columns,index=data.columns)
for i in data.columns:
for j in data.columns:
dfEquals.loc[i,j]=data.loc[:,i].equals(data.loc[:,j])
return dfEquals
detEquals=FeatureEquals(df)
print(detEquals)
city class haha name score_math score_music sex
city True False False False False False False
class False True False False False False False
haha False False True False False False True
name False False False True False False False
score_math False False False False True False False
score_music False False False False False True False
sex False False True False False False True
lenDet=detEquals.shape[0]
dupCol=[]
for k in range(lenDet):
for l in range(k+1,lenDet):
if detEquals.iloc[k,l] & (detEquals.columns[l] not in dupCol):
dupCol.append(detEquals.columns[l])
print(df.shape)
df.drop(dupCol,axis=1,inplace=True)
print(df.shape)
df
(6, 7)
(6, 6)
| city | class | haha | name | score_math | score_music | |
|---|---|---|---|---|---|---|
| 0 | 广州市 | A | 女 | Bob | 99 | 78 |
| 1 | 深圳市 | A | 男 | Bob | 99 | 81 |
| 2 | 上海市 | B | 女 | Mark | 87 | 91 |
| 3 | 重庆市 | B | 女 | Miki | 77 | 72 |
| 4 | 贵州市 | C | 女 | Sully | 77 | 67 |
| 5 | 北京市 | A | 男 | Rose | 65 | 99 |
df = pd.DataFrame({'class':['A','A','B','B','C','A'],
'name':['Bob','Bob','Mark','Miki','Sully','Rose'],
'city':['广州市','深圳市','上海市','重庆市','贵州市','北京市'],
'sex':['女','男','女','女','女','男'],
'score_math':[99,99,87,77,77,65],
'haha':[np.NAN,np.NAN,np.NAN,np.NAN,np.NAN,np.NAN],
'score_music':[78,81,91,72,67,99],
})
# df.loc[:,['class']]
# df[:3]
# df[:3][['class']]
# 删除一列数据全为空或者全为NaN
def dropNullStd(date):
beforelen=date.shape[1]
collisNull=date.describe().loc['count']==0
print(collisNull)
print(type(collisNull))
for i in range(len(collisNull)):
if collisNull[i]:
date.drop(collisNull.index[i],axis=1,inplace=True)
afterlen=date.shape[1]
print(beforelen-afterlen)
print(date.shape)
dropNullStd(df)
df.describe()
haha True
score_math False
score_music False
Name: count, dtype: bool
<class 'pandas.core.series.Series'>
1
(6, 6)
| score_math | score_music | |
|---|---|---|
| count | 6.000000 | 6.000000 |
| mean | 84.000000 | 81.333333 |
| std | 13.549908 | 11.910779 |
| min | 65.000000 | 67.000000 |
| 25% | 77.000000 | 73.500000 |
| 50% | 82.000000 | 79.500000 |
| 75% | 96.000000 | 88.500000 |
| max | 99.000000 | 99.000000 |
df = pd.DataFrame({'class':['A','A','B','B','C','A'],
'name':['Bob','Bob','Mark','Miki','Sully','Rose'],
'city':['广州市','深圳市','上海市','重庆市','贵州市','北京市'],
'sex':['女','男','女','女','女','男'],
'score_math':[99,99,87,77,77,65],
'haha':[np.NAN,np.NAN,np.NAN,np.NAN,np.NAN,np.NAN],
'score_music':[78,81,76,72,67,1],
})
# 定义3O原则来识别异常值
def outRange(Ser1):
boolInd=(Ser1.mean()-3*Ser1.std()>Ser1) | (Ser1.mean()+3*Ser1.std()<Ser1)
print(boolInd)
print(type(boolInd))
index=np.arange(Ser1.shape[0])[boolInd]
print(index)
print(type(index))
outrange=Ser1.iloc[index]
return outrange
outlier=outRange(df['score_music'])
print(outlier.shape[0])
print(outlier.max())
print(outlier.min())
0 False
1 False
2 False
3 False
4 False
5 False
Name: score_music, dtype: bool
<class 'pandas.core.series.Series'>
[]
<class 'numpy.ndarray'>
0
nan
nan
# 箱形图四分位数处理异常值
def outRange(Ser1):
QL=Ser1.quantile(0.25)
QU=Ser1.quantile(0.75)
IQR=QU-QL
Ser1.loc[Ser1>(QU+1.5*IQR)]=QU
Ser1.loc[Ser1<(QU-1.5*IQR)]=QL
return Ser1
df['score_music']=outRange(df['score_music'])
print(df['score_music'].min())
print(df['score_music'].max())
67.0
81.0
E:\anaconda\lib\site-packages\pandas\core\indexing.py:179: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
self._setitem_with_indexer(indexer, value)
# boolInd=pd.Series([False,True,True,False,False],dtype=bool)
boolInd=[False,True,True,False,False]
print(boolInd)
index=np.arange(5)[boolInd]
print(index)
[False, True, True, False, False]
[1 2]
df = pd.DataFrame({'class':['A','A','B','B','C','A'],
'name':['Bob','Bob','Mark','Miki','Sully','Rose'],
'city':['广州市','深圳市',np.NAN,'重庆市','贵州市','北京市'],
'sex':['女','男',np.NAN,'女','女','男'],
'score_math':[99,99,87,77,77,65],
'haha':[np.NAN,np.NAN,np.NAN,np.NAN,np.NAN,np.NAN],
'score_music':[78,81,76,np.NAN,np.NAN,1],
})
naRate=(df.isnull().sum()/df.shape[0]*100).astype('str')+'%'#统计各个特征的缺失率
print(naRate)
city 16.666666666666664%
class 0.0%
haha 100.0%
name 0.0%
score_math 0.0%
score_music 33.33333333333333%
sex 16.666666666666664%
dtype: object
df
| city | class | haha | name | score_math | score_music | sex | |
|---|---|---|---|---|---|---|---|
| 0 | 广州市 | A | NaN | Bob | 99 | 78.00 | 女 |
| 1 | 深圳市 | A | NaN | Bob | 99 | 81.00 | 男 |
| 2 | 上海市 | B | NaN | Mark | 87 | 76.00 | 女 |
| 3 | 重庆市 | B | NaN | Miki | 77 | 72.00 | 女 |
| 4 | 贵州市 | C | NaN | Sully | 77 | 67.00 | 女 |
| 5 | 北京市 | A | NaN | Rose | 65 | 68.25 | 男 |
# 等频法,离散化连续型数据(数值型转化为类别型数据)
def SameRateCut(data,k):
w=data.quantile(np.arange(0,1+1.0/k,1.0/k))
data=pd.cut(data,w)#默认左开右闭
return data
result=SameRateCut(df['score_music'],2).value_counts()
print(result)
(74.0, 81.0] 3
(67.0, 74.0] 2
Name: score_music, dtype: int64
# 小数定标标准化数据,将数据映射到[-1,1]区间
def DecimalScaler(data):
data=data/10**np.ceil(np.log10(data.abs().mean()))
return data
data1=DecimalScaler(df['score_math'])
data2=DecimalScaler(df['score_music'])
data3=pd.concat([data1,data2],axis=1)
print(df[['score_music','score_math']].head())
print(data3.head())
score_music score_math
0 78.0 99
1 81.0 99
2 76.0 87
3 72.0 77
4 67.0 77
score_math score_music
0 0.99 0.78
1 0.99 0.81
2 0.87 0.76
3 0.77 0.72
4 0.77 0.67
def KmeanCut(data,k):
from sklearn.cluster import KMeans
kmodel=KMeans(n_clusters=k)
kmodel.fit(data.values.reshape((len(data),1)))
c=pd.DataFrame(kmodel.cluster_centers_).sort_values(0)
w=c.rolling(2).mean().iloc[1:]
w=[0]+list(w[0])+[data.max()]
data=pd.cut(data,w)
return data
result=KmeanCut(df['score_math'],2).value_counts()
print(result)
(0.0, 84.0] 3
(84.0, 99.0] 3
Name: score_math, dtype: int64
numpy“通用函数”(ufunc)包括以下几种:
- 元素级函数(一元函数):对数组中的每个元素进行运算
- 数组级函数:统计函数,像聚合函数(例如:求和、求平均)
- 矩阵运算
- 随机生成函数
| 函数名 | 作用 | 例子 | 结果 |
|---|---|---|---|
| np.abs()、sum()、mean()std()、var() | 计算绝对值、求和、求平均值求标准差、方差 | arr = np.array([1,2,-3,-4,5])np.abs(arr) | array([1, 2, 3, 4, 5]) |
| np.min()、max()、argmin ()、argmax() | 最小值、最大值、最小值索引、最大值索引 | arr = np.array([1.1,2.2,-3.3]) np.argmin(arrr) | 2 |
| np.square() | 计算各元素的平方 | arr = np.array([1,2,-3,-4,5])np.square(arr) | array([ 1, 4, 9, 16, 25], dtype=int32) |
| np.sqrt() | 计算各元素的平方根 | arr = np.array([1,2,4,5])np.sqrt(arr) | array([1. , 1.41421356, 2. , 2.23606798]) |
| np.exp() | 计算各元素以e为底的指数(ex) | arr = np.array([1,2,4,5]) np.exp(arr) | array([ 2.71828183, 7.3890561 , 54.59815003, 148.4131591 ]) |
| np.log()、log10()、log2() | 计算以e、10、2为底的对数 | arr = np.array([10,100,1000]) np.log10(arr) | array([1., 2., 3.]) |
| np.sign() | 返回各元素的正负号:1(正数)、0(零)、-1(负数) | arr = np.array([1,2,-3,-4,5,0]) np.sign(arr) | array([ 1, 1, -1, -1, 1, 0]) |
| np.sort() | 对数组进行排序(默认升序) 多维数组可以在单个轴上进行排序 | arr = np.array([1,2,-3,-4,5,0]) np.sort(arr) | array([-4, -3, 0, 1, 2, 5]) |
| np.unique() | 去重—>结果默认升序排列同python中的集合set() | arr = np.array([1,2,-3,2,1,0])arr.unique() | array([-3, 0, 1, 2]) |
| np.ceil() | 向上取整 | arr = np.array([1.1,2.2,-3.3]) np.ceil(arr) | array([ 2., 3., -3.]) |
| floor() | 向下取整 | arr = np.array([1.1,2.2,-3.3]) np.floor(arr) | array([ 1., 2., -4.]) |
| np.rint() | 四舍五入 | arr = np.array([1.1,2.2,-3.3]) np.rint(arr) | array([ 1., 2., -3.]) |
| np.modf() | 小数和整数分离 | arr = np.array([1.1,2.2,-3.3]) np.modf(arr) | (array([ 0.1, 0.2, -0.3]), array([ 1., 2., -3.])) |
| np.sin()、cos()、tan() | 正弦、余弦、正切 | 同上 | |
| np.cumsum() | 求数组元素累计和 | arr = np.array([1,2,3]) np.cumsum(arr) | array([1, 3, 6], dtype=int32) |
| np.cumprod() | 求数组元素的累积积 | arr = np.array([1,2,3]) np.cumprod(arr) | array([1, 2, 6], dtype=int32) |
二、numpy.linalg模块包括许多矩阵运算
常用的有:
| 函数名 | 作用 | 例子 | 结果 |
|---|---|---|---|
| np.diag() | 返回矩阵的主对角线元素,若输入一维数组则返回对角矩阵 | arr=np.array([[1,2,3],[2,2,3],[3,5,1]]) np.diag(arr) | array([1, 2, 1]) |
| np.trace() | 计算对角线元素之和 | np.trace(arr) | 4 |
| np.linalg.det() | 计算矩阵的行列式 | np.linalg.det(arr) | 12.999999999999995 |
| np.linalg.inv() | 计算矩阵的逆 | np.linalg.inv(arr) | array([[-1.00000000e+00, 1.00000000e+00, -9.25185854e-18], [ 5.38461538e-01, -6.15384615e-01, 2.30769231e-01], [ 3.07692308e-01, 7.69230769e-02, -1.53846154e-01]]) |
| np.dot() | 矩阵点乘 | arr2 = np.array([[1,2],[2,3],[3,4]]) np.dot(arr,arr2) | array([[14, 20], [15, 22], [16, 25]]) |
三、numpy.random模块包括许多生成随机数的函数
常用的有:
| 函数名 | 作用 | 例子 | 结果 |
|---|---|---|---|
| np.random.rand() | 产生(0,1)均匀分布的随机数 | arr = np.random.rand(2,2) | array([[0.28576059, 0.87691219], [0.98174158, 0.37963998]]) |
| np.random.randint() | 从给定上下限范围内随机选取整数(默认是0-1之间) | arr = np.random.randint(0,5,size=(2,2)) | array([[4, 3], [2, 1]]) |
| np.random.binomial() | 产生二项分布的随机数,有两个参数:n、p;且可用size指定形状 | arr=np.random.binomial(20,0.3) | 7 |
| np.random.normal() | 产生正态分布的随机数有两个参数:均值μ、标准差σ;且可用size指定形状 | arr = np.random.normal(0,0.4,size=(2,2)) | array([[ 0.19689244, 0.1862919 ], [ 0.5238639 , 0.22638041]]) |
| np.random.randn() | 产生标准正态分布的随机数 即均值μ=0、标准差σ=1 | arr = np.random.randn(2,3) | array([[ 0.25079709, -0.35966478, -1.28589538], [-1.02478972, -0.2292332 , -1.40625537]]) |
| np.random.seed() | 确定随机数生成的种子,让生成随机数的过程可重现(不设置seed时,每次生成的随机数将不同) | np.random.seed(5) np.random.rand(2,2)np.random.seed(5) np.random.rand(2,3) | array([[0.22199317, 0.87073231], [0.20671916, 0.91861091]])array([[0.22199317, 0.87073231, 0.20671916], [0.91861091, 0.48841119, 0.61174386]]) |
DataFrame的删除和添加一列
添加一列:(1)像字典一样通过赋值的方式执行
d['three']=d['one']+d['two']
2)使用insert()在指定位置插入一列,例如在位置1插入新的一列’new’,值为0
d.insert(1,'new',np.zeros((4,1)))
删除一列:像字典一样——>使用pop()或者del(),pop()可以在删除列的基础之上将删除的列赋值给一个新的变量
del d['three']
new = d.pop('new')
DataFrame修改索引名:使用rename()方法
i = {'a':'A','b':'B'}
d.rename(index=i)#行索引改名
常用的描述性统计函数、汇总函数
| 函数 | 作用 | 函数 | 作用 |
|---|---|---|---|
| count | 非缺失样本的数量 | sum | 求和 |
| mean | 均值 | mad | 平均绝对偏差(Mean absolute deviation) |
| median | 中位数 | min | 最小值 |
| max | 最大值 | mode | 众数 |
| abs | 绝对值 | prod | 乘积 |
| std | 标准差 | var | 无偏方差 |
| sem | 平均标准误差 | skew | 偏度(三阶矩) |
| kurt | 峰度(四阶矩) | quantile | 分位数 |
| cumsum | 累计求和 | cumprod | 累积 |
| cummax | 累计最大值 | cummin | 累积最小值 |
二、汇总函数
(1)describe():查看各个特征的均值、标准差、最小值、最大值即分位数,对样本数据量进行统计,默认仅对数值型数据进行统计,也可通过上一节数据筛选中所说的include和exclude来设定包括或是剔除哪些类型的特征。
例如:>>>df.describe(include=[‘object’])
需要注意的是:
- describe()返回的对象也是一个DataFrame类型,所以我们是可以根据自身需求提取需要的汇总量;
- describe()也可以对非数值型数据进行统计,只是统计指标不同而已.
(2)info():显示各个特征数据类型、非空值数量、总体样本量、占用的内存空间;
若不关心其中缺失值的情况,则可设置null_counts参数的值为False;